Mit dem Aufkommen von Elektrofahrzeugen, der Entwicklung von Technologien für autonomes Fahren und der Beliebtheit von Shared-Mobility-Modellen ist der Automobilmarkt immer wettbewerbsintensiver geworden. Vor diesem Hintergrund ist der Zugang zu genauen Marktdaten entscheidend geworden. Das Web-Scraping für Automobildaten als effizientes Mittel zur Datenerfassung kann Unternehmen dabei helfen, Einblicke in Markttrends zu gewinnen, Wettbewerber zu analysieren und das Verbraucherverhalten vorherzusagen, um so einen Vorteil im harten Marktwettbewerb zu erlangen. In diesem Artikel befassen wir uns mit der Bedeutung des Crawlings von Automobildaten und stellen einige praktische Methoden und Tipps für das Crawling von Daten vor, mit denen Sie wertvolle Einblicke in den Markt der Automobilindustrie gewinnen können.
Warum ist Auto-Daten-Scraping wichtig
Bei der Crawler-Technologie handelt es sich um eine automatisierte Daten-Crawling-Technologie, die das menschliche Browserverhalten simulieren kann, um eine große Menge an automobilbezogenen Daten aus dem Internet zu erhalten. Sie können auf Datenquellen wie die Websites von Autoherstellern, Online-Autohandelsplattformen wie Auto Scout24, mobile.de und autodoc.de, soziale Medien und Automobilnachrichtenseiten wie Auto Bild, Auto Zeitung und Autohaus zugreifen, um Daten zu Autoverkaufsdaten, Markttrends und neuen Fahrzeugveröffentlichungen wie dem Xiaomi SU7 zu erhalten.
👉 Grund 1: Wir können die Crawler-Technologie nutzen, um Marktwettbewerbsanalysen durchzuführen. Durch das Crawlen von Daten aus den offiziellen Websites der Wettbewerber, Social-Media-Plattformen, Online-Rezensionen und anderen Kanälen ist es möglich, die Produktmerkmale, Preisstrategien, Marktanteile und andere Informationen der Wettbewerber zu verstehen. Darüber hinaus können durch das Crawlen von Verbraucherkommentaren und -bewertungen zu Automarken und -modellen auch Verbraucherpräferenzen und -bedürfnisse analysiert werden, was den Unternehmen Anhaltspunkte für ihre Produktentwicklung und Marktpositionierung liefert.
👉 Grund 2: Durch das Crawlen von Daten auf den offiziellen Websites der Wettbewerber, auf Social-Media-Plattformen, in Online-Rezensionen und anderen Kanälen ist es möglich, die Produktmerkmale, Preisstrategien, Marktanteile und andere Informationen der Wettbewerber zu verstehen. Außerdem können wir durch das Crawlen von Verbraucherkommentaren und -bewertungen zu Automarken und -modellen die Vorlieben und Bedürfnisse der Verbraucher analysieren und den Unternehmen Anhaltspunkte für ihre Produktentwicklung und Marktpositionierung liefern.
👉 Grund 3: Die Crawling-Technologie kann auch mit anderen Datenanalysetechniken wie maschinellem Lernen und künstlicher Intelligenz kombiniert werden, um eine tiefer gehende Analyse des Wettbewerbsmarktes zu ermöglichen. Durch Mustererkennung und prädiktive Analyse großer Mengen von Crawler-Daten können potenzielle Marktchancen und Wettbewerbsrisiken ermittelt werden. So lassen sich beispielsweise künftige Markttrends und das Verbraucherverhalten durch die Analyse der Marketingstrategien der Wettbewerber und des Verbraucherfeedbacks vorhersagen, was eine wissenschaftliche Grundlage für die Entscheidungsfindung von Unternehmen darstellt.
Der Einsatz von Crawlern zur Datenerfassung und Wettbewerbsanalyse in der Automobilindustrie ist von großer Bedeutung. Mit Hilfe der Crawler-Technologie können wir umfangreiche automobilbezogene Daten erfassen und durch Datenanalyse wertvolle Markteinblicke und Wettbewerbsvorteile ableiten. Dies wird Unternehmen dabei helfen, Chancen zu nutzen und Herausforderungen in der hart umkämpften Automobilindustrie zu meistern, um eine nachhaltige Entwicklung und Marktführerschaft zu erreichen.
So führen Sie das Auto-Daten-Scraping durch
Im Allgemeinen ist das Scraper öffentlicher Informationen von Websites legal, wohingegen das Scraper privater Kontodaten Datenschutzbedenken aufwirft.
Wenn Sie das Webcrawling für Ihre eigenen Zwecke nutzen, ist es legal, da es unter die Fair-Use-Doktrin fällt, z. B. für Marktforschung und wissenschaftliche Forschung. Aber wenn Sie die gesammelten Daten für andere verwenden wollen, insbesondere kommerzielle Zwecke, ist das illegal.
Um nicht in Rechtsstreitigkeiten verwickelt zu werden, finden Sie im Folgenden eine nicht erschöpfende Liste praktischer Tipps für Benutzer, die sich mit Web Scraping beschäftigt haben.
Respektieren und befolgen Sie die Nutzungsbedingungen
Lesen Sie stets die Nutzungsbedingungen (AGB) und die robot.txt-Dateien der Website, bevor Sie einer Web-Scraping-Datenerfassungsaktivität zustimmen. Wenn möglich, holen Sie die vorherige Genehmigung des Eigentümers der Website ein.
Schaben Sie mit angemessener und mäßiger Geschwindigkeit
Seien Sie sanft und nicht aggressiv. Geben Sie der geschabten Website etwas Luft zum Atmen. Beim Scraping sollten Sie die Website innerhalb eines angemessenen Zeitintervalls aufrufen und die Anzahl der Anfragen unter Kontrolle halten. Vermeiden Sie eine Beeinträchtigung des physischen Betriebs einer Website, da dies zu einer Klage wegen unerlaubten Zugriffs auf bewegliche Sachen oder ähnlichem führen könnte.
Überwachen und erwägen Sie alle Maßnahmen, die eine Website ergreift, um Web Scraping einzuschränken
Wenn eine Website Ihre Web-Scraping-Aktivitäten durch verschiedene Anti-Scraping-Maßnahmen, wie die Verwendung von CAPTCHAs, Ratenbegrenzungen, Sperrung von IP-Adressen usw., deutlich einschränkt, müssen Sie sich vor möglichen rechtlichen Risiken in Acht nehmen. Seien Sie darauf vorbereitet, aufzuhören, wenn Sie durch eine Unterlassungserklärung oder auf andere Weise dazu aufgefordert werden.
Vermeiden Sie es, personenbezogene Daten zu sammeln
Überlegen Sie, ob die zu löschenden Daten zu den personenbezogenen Daten von EU-Bürgern gehören. Sie können diese Daten nur aus einem der folgenden fünf Gründe löschen:
- Einwilligung – Die Einwilligung der betroffenen Person
- Vertrag – Ein Vertrag mit der betroffenen Person
- Compliance – Notwendigkeit zur Einhaltung einer rechtlichen Verpflichtung.
- Lebenswichtiges Interesse, öffentliches Interesse oder offizielle Autorität – Im Interesse der Öffentlichkeit.
- Berechtigtes Interesse – Notwendigkeit für andere berechtigte Interessen
Überlegen Sie, ob die zu extrahierenden Daten urheberrechtlich geschützt sind
Kratzen Sie nicht die urheberrechtlich geschützten oder patentierten Daten, da Sie sonst in eine Urheberrechtsverletzung verwickelt sein könnten.
Nutzen Sie die geschabten Daten sinnvoll
Geben Sie die abgekratzten Daten nicht wahllos an andere weiter. Nutzen Sie Daten sinnvoll, um mehr Erkenntnisse zu gewinnen und Ihr Unternehmen zu verbessern.
2 kostenlose Methoden des Daten-Scrapings im Auto-Sektor
Python
Wenn Sie Python verwenden, benötigen Sie Programmierkenntnisse, insbesondere die Python-Sprache und verwandte Bibliotheken wie Requests, BeautifulSoup, Selenium usw. Wenn sich außerdem die Struktur der Zielwebsite ändert, müssen Sie möglicherweise Ihren Crawler-Code regelmäßig aktualisieren und warten.
Das Crawlen von Autodaten mit Python umfasst in der Regel die folgenden Schritte:
- Bestimmen Sie die Ziel-Websites: Zunächst müssen Sie bestimmen, welche Websites die Autodaten enthalten, die Sie crawlen möchten. Dies könnte die offizielle Website eines Autoherstellers, eine Autoverkaufsplattform, eine Website mit Fahrzeugbewertungen usw. sein.
- Analysieren Sie die Webstruktur: Bevor Sie mit dem Schreiben des Crawler-Codes beginnen, müssen Sie die HTML-Struktur der Ziel-Website analysieren. Das können Sie mit den Entwickler-Tools Ihres Browsers tun. Sie müssen die HTML-Tags und Attribute finden, die Autodaten enthalten.
- Auswahl der richtigen Bibliothek: Python verfügt über mehrere leistungsstarke Bibliotheken, die zum Schreiben eines Crawlers verwendet werden können, z. B. requests zum Senden von HTTP-Anfragen, BeautifulSoup oder lxml zum Parsen von HTML-Dokumenten und selenium zum Simulieren von Browseraktionen.
- Schreiben Sie den Crawler-Code
- Verwenden Sie requestss, um den Inhalt der Webseite zu erhalten. Verwenden Sie BeautifulSoup oder lxml, um das HTML zu parsen und die erforderlichen Daten zu extrahieren. Wenn die Website einen Anti-Crawler-Mechanismus hat oder komplexe Benutzerinteraktionen simulieren muss, können Sie Selenium verwenden.
- Datenspeicherung: Speichern Sie die extrahierten Daten in einem geeigneten Format, z. B. als CSV-Datei, Datenbank oder JSON-Datei.
- Einhaltung von Gesetzen und Vorschriften: Halten Sie beim Crawlen von Daten die Nutzungsbedingungen der Zielwebsite ein und respektieren Sie Urheberrechts- und Datenschutzvorschriften.
- Behandlung von Ausnahmen und Optimierung: Berücksichtigen Sie die Behandlung von Ausnahmen während des Crawler-Betriebs, z. B. bei fehlgeschlagenen Netzwerkanfragen, Parsing-Fehlern und so weiter. Optimieren Sie gleichzeitig den Code, um die Crawling-Effizienz zu verbessern und die Häufigkeit der Anfragen an den Server der Ziel-Website zu verringern.
- Datenbereinigung: Die gecrawlten Daten können unbrauchbare oder ungenaue Informationen enthalten; eine Datenbereinigung ist erforderlich, um die Datenqualität zu verbessern.
- Aktualisierung: Da sich die Struktur der Website ändern kann, ist es wichtig, den Crawler-Code regelmäßig zu aktualisieren, um diesen Änderungen Rechnung zu tragen.
Hier ist ein einfaches Beispiel für einen Python-Crawler:
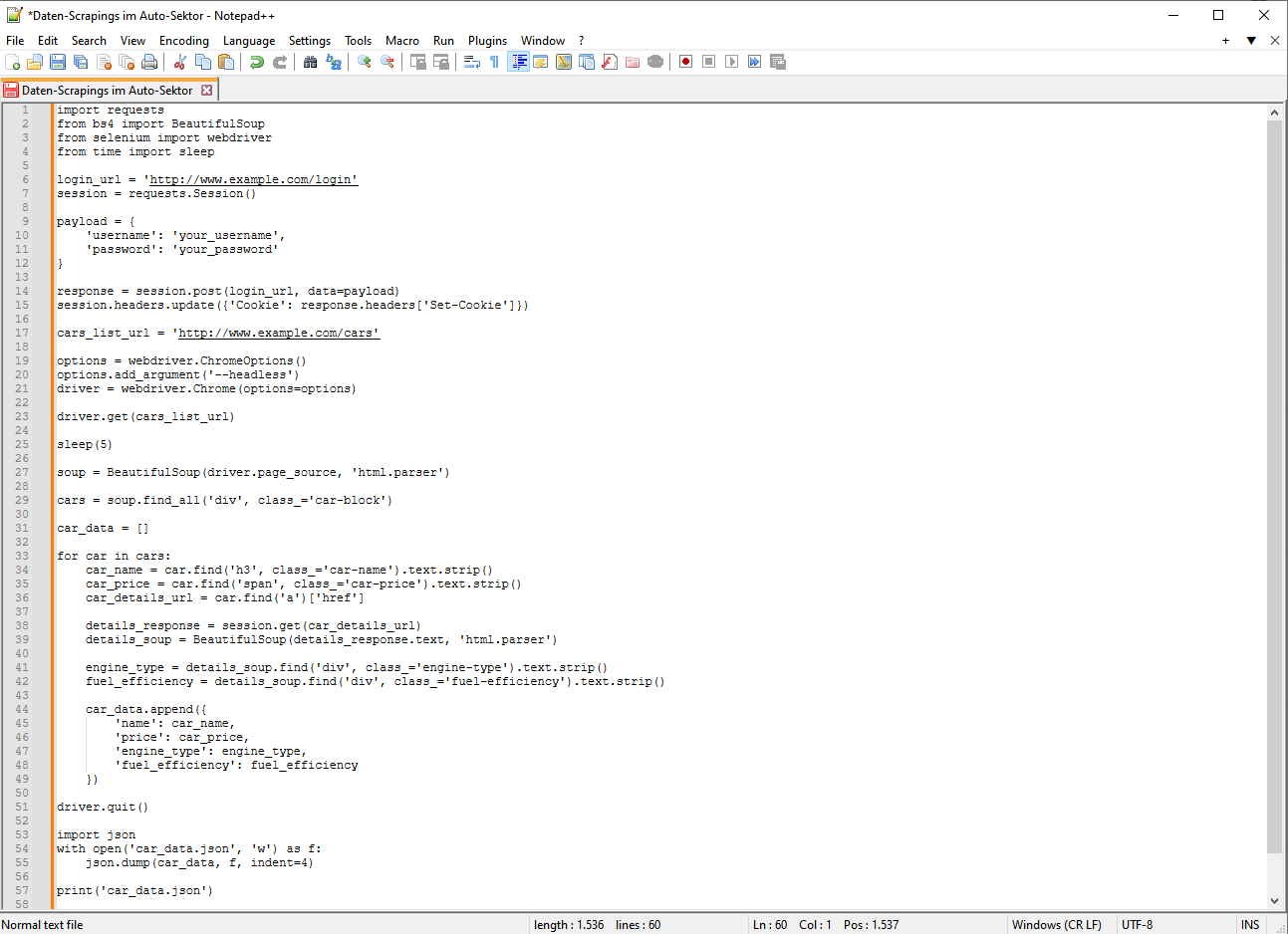
Bitte beachten Sie, dass es sich hierbei um ein einfaches Beispiel handelt. Der tatsächliche Crawler kann komplexer sein und muss Paging, Logins, AJAX-Anfragen und viele weitere Szenarien verarbeiten. Darüber hinaus werden die genauen Implementierungsdetails je nach Zielsite stark variieren. Aber wenn Sie ein Crawler-Tool verwenden, wird es effizient sein.
Wenn Sie Daten schnell crawlen möchten und keine Programmiererfahrung haben, sind kostenlose Crawler-Tools besser für Sie geeignet.
Octoparse – das KOSTENLOSE Auto-Daten-Scraping-Tool 🔨
👍 Kosten: Kostenloser Plan oder Standard-Plan ab 75 $/Monat (Kostenlose Testversion für 14 Tage verfügbar)
👍 Unterstützte Plattformen: Desktop-basiert und browserbasiert
Wenn Sie noch nicht so gut im Codieren sind, ist Octoparse das perfekte Tool für Sie, um den ersten Schritt zu machen. Als programmierungsfreie Web-Scraping-Lösung ist Octoparse dafür konzipiert, dass jeder Seiten mit Klicks in strukturierte Dateien umwandeln kann. Mit seinen erweiterten Funktionen kann es auch die Rolle des KI-Web-Scraping-Assistenten übernehmen, zum Beispiel:
- Automatische Erkennung: Diese Funktion scannt automatisch die Seite und findet extrahierbare Fahrzeuginformationen, wie z. B. den Preis.
- Automatisch generierter Workflow: Ein Workflow auf Octoparse ist ein Flussdiagramm, das jede Aktion eines Scrapers zeigt. Octoparse visualisiert den Scraping-Prozess, sodass Sie ganz einfach eine Vorschau der Scraper anzeigen können, ohne dass Sie eine Codezeile schreiben müssen.
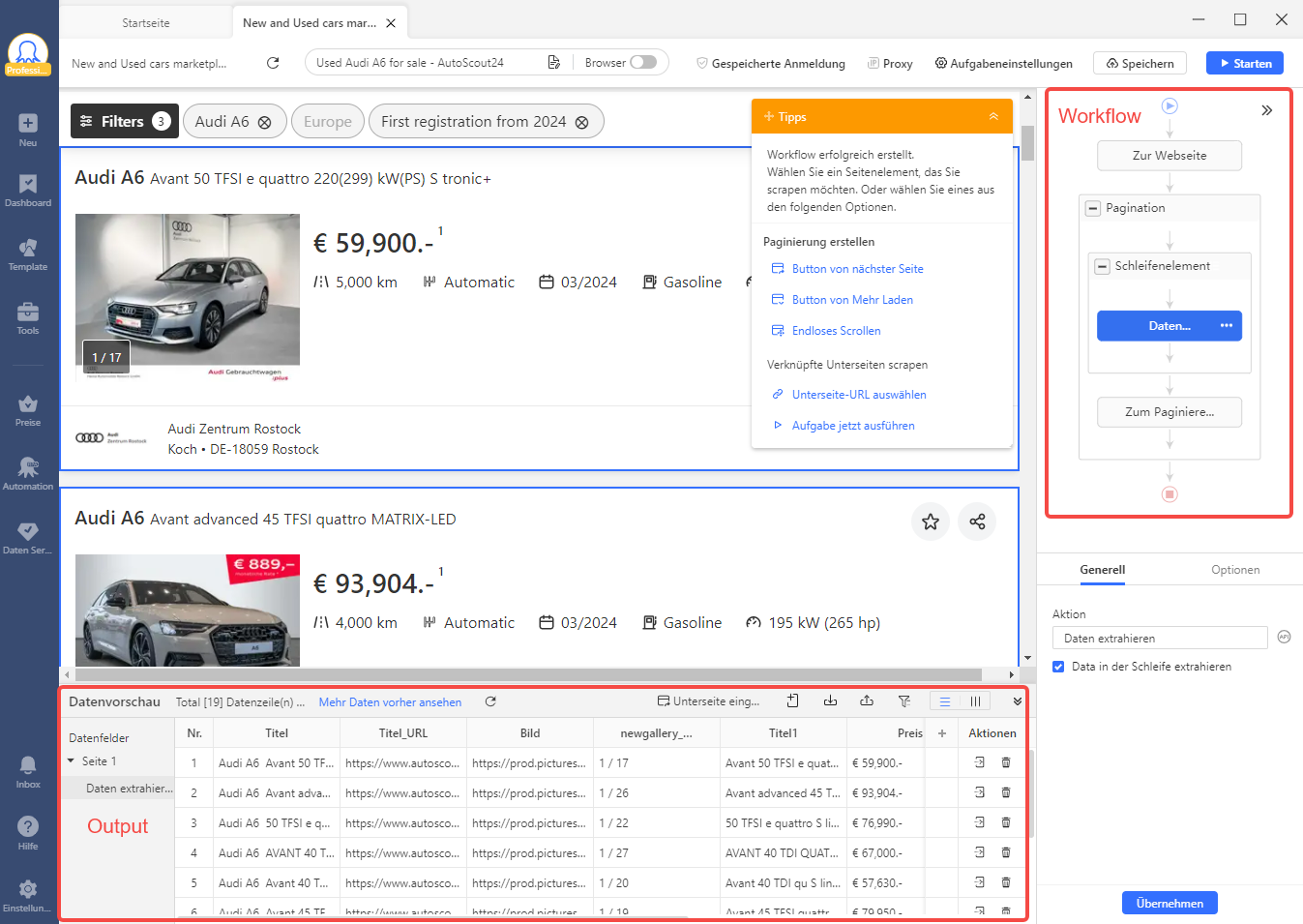
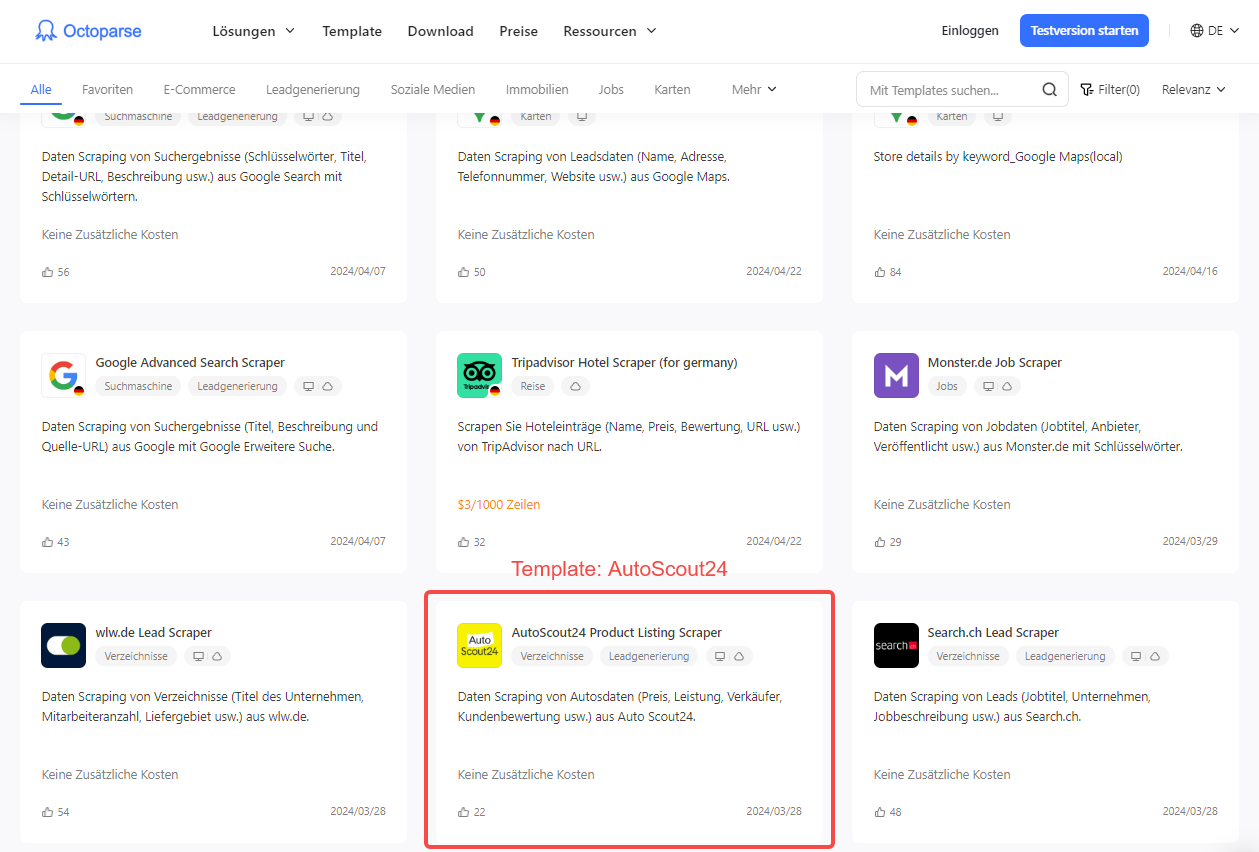
- Vorlagen: Voreingestellte Vorlagen ermöglichen Ihnen das Scrapen von Daten, indem Sie nur einige erforderliche Parameter eingeben. Jetzt bietet Octoparse viele Vorlagen für die beliebtesten Online-Autohandelsplattformen wie AutoScout24. Sie können diese Vorlagen nicht nur in der Desktop-basierten Software verwenden, sondern auch in Ihrem Browser auf der Seite „Octoparse Web Scraping-Vorlagen“ .
Zusammen mit diesen Funktionen vereinfacht Octoparse den Web-Scraping-Prozess in jeder Phase. Sie können Auto-Daten-Scraping so planen, dass sie regelmäßig ausgeführt werden und die Scraping-Daten automatisch exportieren. Darüber hinaus werden die Stärken des Systems in den Bereichen IP-Rotation und CAPTCHA-Lösungen Ihre Effizienz beim Abrufen von Fahrzeuginformationen von Websites erhöhen.
Zusammenfassung
Mit den oben genannten detaillierten Analysen und praktischen Anleitungen haben Sie die Schlüsselkompetenzen für das Crawling von Fahrzeugdaten erlernt. Jetzt ist es an der Zeit, dieses Wissen anzuwenden und das Potenzial Ihrer Daten zu erschließen, um Ihr Unternehmen zu Erkenntnissen und Marktgewinnen in der Automobilindustrie zu führen. Handeln Sie jetzt und lassen Sie Daten Ihre Entscheidungen beeinflussen!
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



