Twitter, heute als X bekannt, ist eine der beliebtesten sozialen Plattformen. Hier kann es vielleicht interessant sein, was berühmte Persönlichkeiten sagen. Doch auch interessante Geschäftskontakte können hier geknüpft werden. Viele nutzen Twitter auch um Markttrends zu verfolgen. Fragen Sie sich dabei, wie Sie so viele Daten in Formatdateien wie Excel, CSV, Google Sheets oder sogar in die Datenbank extrahieren können?
In diesem Artikel erfahren Sie, wie Sie Twitter-Daten wie Tweets, Kommentare, Hashtags, Bilder usw. mit dem besten Twitter Crawler scrapen. Das Twitter scraping ist innerhalb von 5 Minuten abgeschlossen. Alles funktioniert ohne, dass man API, Tweepy, Python oder eine einzige Codezeile verwenden muss.
Twitter scraping – ist es legal?
Grundsätzlich ist das Web scraping Twitter öffentlicher Daten legal. Doch sollten Sie stets die urheberrechtlichen Bestimmungen und Datenschutzbestimmungen beachten. Es kommt auch darauf an, wofür Sie die Daten verwenden möchten. Beachten Sie die lokalen Gesetze. In unserem Artikel zum Thema Twitter Scraping können Sie mehr erfahren.
Wenn Sie sich hinsichtlich der Legalität oder Compliance unsicher fühlen, können Sie die Twitter-API ausprobieren. Diese bietet fortgeschrittenen Benutzern mit Programmierkenntnissen Zugriff auf Twitter. Sie können Informationen wie Tweets, Direktnachrichten, Spaces, Listen, Benutzer und mehr abrufen.
Welche Daten kann man auf Twitter scrapen?
Beim Twitter Scraping dürfen ausschließlich öffentliche Daten angewendet werden. Es ist möglich, dass man die sichtbaren Twitter-Daten wie Tweets, Hashtag, Kommentare scrapen kann. Außerdem müssen Sie auch die Nutzungsregeln von Twitter beachten.
Twitter ändert sich zu X, was sagen die Leute dazu?
Twitter änderte am 24. Juli 2023 sein Logo vom ikonischen blauen Vogel zum X. Ab sofort sehen Sie das brandneue X-Logo auf Twitter.com, und die neue Domain x.com leitet nun auf twitter.com weiter. Auf Twitter werden viele Trendthemen wie #Xeet und #Twitter„X“ diskutiert.
Was halten Sie von der Umbenennung von Twitter in X und was sagen andere dazu? Hier sind drei Tipps zum Twitter scraping von Nachrichten mit Octoparse. Es handelt sich hierbei um das beste Web-Scraping-Tool.
Tipp 1: Kommentare von Elon Musks Tweet scrapen
Elon Musks neuester Tweet lautet „Our headquarters tonight“ und hat bereits fast 40k Kommentare. Und das vorherige Video über das neue Logo, das er getwittert hat, hat bereits 47,5k Kommentare. Es ist ein wichtiger Ort, um zu erfahren, was die Leute über die Änderungen sagen.
Octoparse bietet die Möglichkeiten, Kommentare von Twitter auszulesen. Es gibt zwei Wege, Daten von Twitter zu sammeln. Ein Twitter Crawler kann manuell erstellt werden oder mit einer fertigen Scraping-Vorlage genutzt werden. Für Benutzer mit wenig Erfahrung im Bereich Web Twitter scraping empfiehlt es sich, die voreingestellte Vorlage zu verwenden. Diese ist bereits vorkonfiguriert und einfach über die Octoparse-Plattform ausgeführt. Dadurch sparen Sie Zeit und Aufwand bei der Erstellung des Scrapers. Sie können sich stattdessen auf die Analyse der extrahierten Daten konzentrieren.
Tipp 2: Tweets nach Hashtag scrapen
Man kann unter einem bestimmten Hashtag, wie #Xeet, alle Tweets scrapen. Mit Octoparse gibt es bereits eine Vorlage namens „Tweets details by hashtag_Twitter“. Damit lässt sich Twitter scraping sehr einfach umsetzen. Man erhält dabei automatisch Infos wie die Tweet-URL, den Autor, die Posting-Zeit, Bilder, Videos oder Likes. Sie können natürlich auch manuell die Tweets scrapen. Sie müssen dafür nur einen Twitter-Scraper in Octoparse einrichten.
Tipp 3: Mit Schlüsselwort Tweets scrapen
Wenn die oben genannten Tipps nicht ausreichen, können Sie selbst nach einem Schlüsselwort suchen und die Suchergebnisse herunterladen. Sie können auch eine von Octoparse bereitgestellte Vorlage mit dem Namen Tweets details by search result URL_Twitter verwenden. Sie können auch die folgenden Schritte ausführen, um Tweets selbst zu scrapen.
So scrapen und erhalten Sie Daten von X (Twitter)
Es gibt drei Möglichkeiten, Daten aus X zu extrahieren:
- Verwenden Sie Web-Scraping-Tools
- Verwenden Sie Open-Source-Scraping-Pakete
- Verwenden Sie die X-API
- Verwenden Sie Web-Scraping-Tools
Ein Web-Scraping-Tool ist ein Softwaredienst, der automatisch Informationen von Websites extrahiert. Im Allgemeinen ist für die Durchführung von Web Twitter Scraping eine Programmierung mit Python usw. erforderlich.
Mit Web-Scraping-Tools können Sie Twitter scraping jedoch mit einfachen Klicks und ohne Programmierung durchführen. Man kann sagen, dass dies die effizienteste Methode beim Scrapen von X-Post-Daten ist.
Verwenden Sie die X-API
Die X-API kann eine Vielzahl von Daten abrufen, da Twitter die Daten bereitstellt. Die Hauptmerkmale und Preise sind wie folgt.
Verwenden Sie die X-API
Die X-API kann eine Vielzahl von Daten abrufen, da Twitter die Daten bereitstellt. Die Hauptmerkmale und Preise sind wie folgt.
| planen | Monatliche Gebühr | Monatliches Beitragslimit | Hauptmerkmale |
| Frei | frei | 1.500 Beiträge | Grundlegender API-Zugriff und Posten von Tweets |
| Basic | 100$/Monat | 50.000 Beiträge | Erweiterter API-Zugriff, Datenerfassung in Echtzeit |
| Profi | 1.500$/Monat | 1.000.000 Beiträge | Weiter erweiterter API-Zugriff, massive Datenerfassung |
| Unternehmen | Brauch | keine Begrenzung | Vollständiger API-Zugriff, benutzerdefinierte Funktionen und Support |
Verwenden Sie Open-Source-Scraping-Pakete
Open Source ist Quellcode, der kostenlos zur Verfügung gestellt wird, sodass jeder ihn nutzen und bearbeiten kann. Sie können mit Open-Source-Scraping-Paketen kostenlos scrapen. Um ein Scraping-Programm zu erstellen, müssen Sie sich jedoch Programmierkenntnisse aneignen.
Open Source wird oft von Communities und Organisationen gepflegt. Deshalb kommen Updates oder Fehlerbehebungen manchmal später.
Web-Scraping-Tools eignen sich am besten für Anfänger zum Scrapen von X-Daten (Twitter).
Wie oben erläutert, empfehlen wir Anfängern, beim Web Twitter Scraping von X-Daten ein Web-Scraping-Tool zu verwenden. Im Vergleich zu anderen Methoden können Daten einfach und mit einfachen Handgriffen erfasst werden. Dadurch sparen Sie sich nicht nur Kosten, sondern vor allem auch Zeit.
Octoparse ist ein Web-Scraping-Tool, das Daten automatisch extrahieren kann. Dafür sind nur einfache Einstellungen nötig, ganz ohne Programmieren. Sie können Tausende von Beiträgen in nur 10 Minuten scrapen. Darüber hinaus ist nicht nur die Geschwindigkeit der Datenextraktion hoch. Auch die Installationskosten sind niedrig, da die Nutzung kostenlos ist.
Für den persönlichen Gebrauch reicht der kostenlose Plan aus. Wenn ein Unternehmen hingegen große Datenmengen extrahieren möchte, empfiehlt sich ein kostenpflichtiger Plan. Wählen Sie bei der Nutzung von Octoparse den passenden Plan entsprechend Ihrem Budget und Ihren Anforderungen.
Web-Scraping-Tools eignen sich am besten für Anfänger zum Scrapen von X-Daten (Twitter).
Wie oben erläutert, empfehlen wir Anfängern, beim Scraping von X-Daten ein Web-Scraping-Tool zu verwenden. Im Vergleich zu anderen Methoden können Daten einfach und mit einfachen Handgriffen erfasst werden, was zu erheblichen Zeit- und Kosteneinsparungen führt.
Unter den vielen Web-Scraping-Tools ermöglicht Ihnen „Octoparse“, die Datenextraktion mit einfachen Einstellungen und Vorgängen zu automatisieren, ohne Code schreiben zu müssen. Extrahieren Sie Tausende von Beiträgen in nur 10 Minuten. Darüber hinaus ist nicht nur die Geschwindigkeit der Datenextraktion hoch, sondern auch die Installationskosten sind niedrig, da die Nutzung kostenlos ist.
Für den persönlichen Gebrauch reicht der kostenlose Plan aus. Wenn ein Unternehmen hingegen große Datenmengen extrahieren möchte, empfiehlt sich ein kostenpflichtiger Plan. Wählen Sie bei der Nutzung von Octoparse den passenden Plan entsprechend Ihrem Budget und Ihren Anforderungen.
Twitter Scraper Tool: Octoparse Schritt-für-Schritt Anleitung
Für das Twitter scraping, ohne zu programmieren, können Sie Octoparse verwenden. Es ist ein Web Scraper, der die menschliche Interaktion mit Webseiten simuliert. Es ermöglicht Ihnen, alle Informationen zu extrahieren, die Sie auf jeder Website sehen, einschließlich Twitter. Nach dem Web Twitter Scraping können Sie die Twitter-Daten dann in Excel-Tabellen, CSV, HTML und SQL exportieren oder sie in Echtzeit über Octoparse-APIs in Ihre Datenbank streamen.
Schritt 1: Geben Sie die URL ein und erstellen Sie das Umblättern
Bevor wir die Anleitung ansehen, können Sie zuerst Octoparse herunterladen. Nehmen wir an, dass wir versuchen, alle Tweets eines bestimmten Benutzers zu crawlen. In diesem Fall setzen wir auf Twitter scraping mit dem offiziellen Twitter-Account von Octoparse. Sie können beobachten, dass die Website im integrierten Browser geladen wird. Normalerweise haben viele Websites eine Schaltfläche „Nächste Seite“. Octoparse kann auf diese klicken, um weitere Inhalte zu erhalten. Bei Web Twitter scraping kann man schnell erkennen, dass Twitter die Technik „Unendliches Scrollen“ nutzt. Dadurch müssen Sie die Seite zuerst nach unten scrollen, damit weitere Tweets geladen werden. Anschließend werden die angezeigten Daten extrahiert. Der endgültige Prozess läuft so ab: Der Twitter Crawler scrollt die Seite ein Stück herunter. Dann werden die Tweets extrahiert und er scrollt nochmal. Dieser Ablauf wird so lange wiederholt, bis alle benötigten Daten vorliegen.
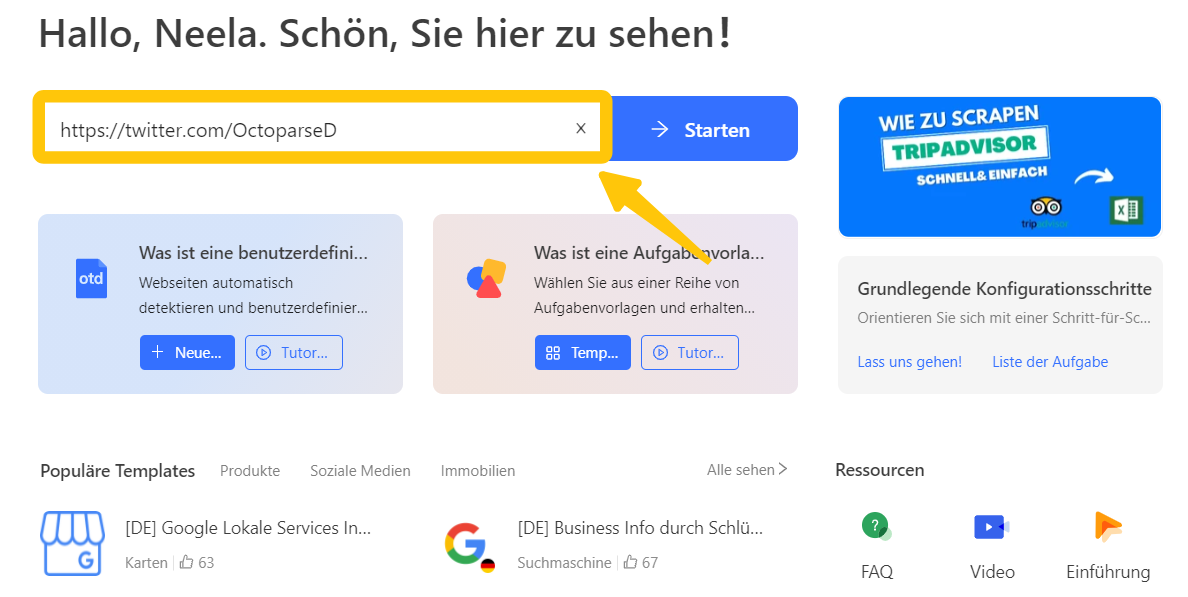
Geben Sie die URL ein und erstellen Sie das Umblättern
Damit der Bot die Seite automatisch nach unten scrollt, muss ein Umblättern eingerichtet werden. Dafür klickt man auf einen leeren Bereich und wählt im Tipps-Panel „loop click single element“. Dann wird im Workflow-Bereich eine Paginierungsschleife angezeigt, was bedeutet, dass wir erfolgreich das Umblättern eingestellt haben.
Schritt 2: Erstellen Sie „Loop Item“, um die Daten zu extrahieren
Zuerst wird im zweiten Schritt ein Tweet-Scraper erstellt. Angenommen, wir möchten die folgenden Informationen extrahieren: Name, Veröffentlichungszeit, Textinhalt, Anzahl der Kommentare, Retweets und Likes.
Zunächst erstellen wir eine Extraktionsschleife, um die Tweets abzurufen. Das ist ein wichtiger Schritt beim Twitter Scraping mit einem Twitter Crawler. Wir können mit dem Cursor auf die Ecke des ersten Tweets klicken. Wenn es grün hervorgehoben ist, erkennt Octoparse alle ähnlichen Elemente automatisch. Alternativ können Sie den Vorgang auch beim zweiten Tweet wiederholen, um alle Items auszuwählen. Nach der Auswahl klicken Sie auf „Text“ unter „Daten extrahieren“. So wird die Extraktionsschleife in den Workflow eingebaut.
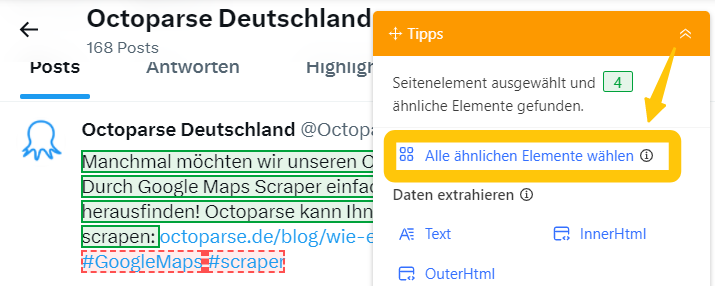
Erstellen Sie „Loop Item“, um die Daten zu extrahieren
Falls wir verschiedene Datenfelder in separate Spalten extrahieren möchten, müssen wir die Extraktionseinstellungen anpassen und die Zieldaten manuell auswählen. Das ist sehr einfach. Suchen Sie im Workflow den Schritt „Daten extrahieren“. Klicken Sie dort auf den Namen des Benutzers und dann auf „Text“. Wiederholen Sie diesen Vorgang für alle gewünschten Datenfelder. Wenn Sie fertig sind, löschen Sie die erste, unnötige Spalte und speichern Sie den Tweet Scraper. So funktioniert Twitter Scraping mit einem Twitter Crawler besonders effizient.
Schritt 3: Ändern Sie die Einstellung des Umblätterns und führen Sie den Crawler aus
Wir haben bereits eine Paginierungsschleife erstellt, aber wir müssen noch eine kleine Änderung an der Workflow-Einstellung vornehmen. Da wir wollen, dass Twitter den Inhalt vollständig lädt, bevor der Bot ihn extrahiert, stellen wir eine AJAX-Wartezeit auf 5 Sekunden ein, damit Twitter nach jedem Scrollen 5 Sekunden Zeit zum Laden hat. Dann legen wir sowohl die Scroll-Wiederholungen als auch die Wartezeit auf 2 fest, um sicherzustellen, dass Twitter den Inhalt erfolgreich lädt. Jetzt wird Octoparse jedes Mal 2 Bildschirme nach unten scrollen, und jeder Bildschirm wird 2 Sekunden dauern.
Gehen Sie zurück zu den Einstellungen für „Schleife“ und wählen Sie den Modus als „Seite Scrollen“, dann stellen Sie die Anzahl des Scrollens auf 20. Dies bedeutet, dass der Bot das Scrollen 20 Mal wiederholt. Mit diesem Twitter Crawler führen Sie ein effektives Twitter Scraping durch. Sie können diesen Twitter Scraper nun auf Ihrem lokalen Gerät oder auf den Octoparse-Cloud-Servern ausführen, um die Daten beim Web Scraping Twitter zu erhalten oder herunterzuladen.
https://www.octoparse.de/template/tweets-&-comments-scraper-by-search-result-url
So scrapen Sie mit der X-API (Twitter)
X bietet eine eigene API an. Damit können viele Funktionen von X verwendet werden. Sie müssen dafür keine offizielle Website öffnen. Die API lässt sich leicht mit verschiedenen Tools verbinden. Sie können zum Beispiel mit Python automatisch Beiträge posten. Auch das Abrufen aller Tweets einer bestimmten Person ist möglich.
Um die API zu nutzen, melden Sie sich bei der X Developer Platform an. Dort müssen Sie dann den Zugriff beantragen. Wird Ihr Antrag geprüft und freigegeben, steht Ihnen die Schnittstelle zur Verfügung. So eröffnen sich viele Möglichkeiten, von Automatisierungen bis hin zu Twitter Scraping.
Allerdings sind Programmierkenntnisse wie Python unerlässlich, um die Datenerfassung mithilfe von APIs zu automatisieren. Für diejenigen ohne Programmierkenntnisse kann dies eine schwierige Hürde sein. Bitte beachten Sie außerdem, dass für die X-API Nutzungsbedingungen gelten und diese daher nur im Rahmen der Nutzungsbedingungen verwendet werden kann.
Informationen zur geschäftlichen Nutzung von X API v2
X API v2 wird in verschiedenen Branchen und Unternehmen häufig verwendet. Nachfolgend finden Sie einige häufige Anwendungsbeispiele.
- Marketing und Kundenservice: Überwachen Sie den Ruf und die Resonanz auf Ihr Unternehmen. Nutzen Sie dann diese Informationen für Ihre Marketingstrategie und Kundeninteraktionen. Mit Web Twitter Scraping und einem Twitter Crawler können Sie gezielt Schlüsselwörter und Hashtags verfolgen. So erkennen Sie Markttrends frühzeitig. Es kann also eine passende Wettbewerbsstrategie entwickelt werden.
- Datenanalyse und Trendforschung: Analysieren Sie das Tweet-Engagement und die Stimmung, um die Wirksamkeit der Kampagne zu bewerten. Sie können auch die Trends Ihrer Wettbewerber recherchieren und diese in Ihrer Geschäftsstrategie berücksichtigen.
- Forschungszweck: Verwendung in der Forschung zu einer Vielzahl von Themen, einschließlich Sozialwissenschaften und Informatik. Während der COVID-19-Pandemie wurde es genutzt, um Veränderungen in Wahrnehmung und Emotionen der Menschen zu untersuchen. Außerdem half es, die Ursachen von Fehlinformationen besser zu verstehen.
Twitter Scraper mit Python
Sie können Twitter Scraper auch mit Python bauen, wenn Sie programmieren können. Dafür gibt es Tools wie Tweepy oder Twint. Dafür brauchen Sie ein Twitter-Entwicklerkonto. Zusätzlich müssen Sie einen API-Zugang beantragen, mit dem Sie Tweets abrufen können. Doch gibt es hier EInschränkungen.
Sobald die Zugänge eingerichtet sind, können Sie mit Ihrem eigenen Twitter Crawler in Python starten. Achten Sie dabei immer auf die API-Richtlinien. Nur so bleiben Sie im erlaubten Rahmen und setzen Twitter Scraping korrekt um.
Wenn Sie nicht programmieren können, gibt es eine einfache Lösung. Web Twitter Scraping mit einem Tool wie Octoparse funktioniert ohne Code. Octoparse ist benutzerfreundlich und perfekt für Anfänger. Zusätzlich bietet das Support-Team schnelle Hilfe, wenn Sie Fragen haben.
FAQ – Web Twitter Scraping
Was versteht man unter Twitter Scraping?
Twitter Scraping bezeichnet das automatische Erfassen von öffentlich zugänglichen Daten. Beispiele dafür sind Tweets, Hashtags oder Kommentare. Mit einem Twitter Crawler lassen sich diese Inhalte strukturiert sammeln und speichern. Web Twitter Scraping macht es möglich, die Daten direkt in Excel, CSV oder Datenbanken zu exportieren.
Ist Web Twitter Scraping legal?
Ja, solange nur öffentliche Daten genutzt werden, ist Twitter Scraping grundsätzlich erlaubt. Achten Sie jedoch auf Datenschutzgesetze, Urheberrechte und die Twitter-Nutzungsbedingungen. Ein Twitter Crawler sollte nur im rechtlichen Rahmen eingesetzt werden.
Brauche ich Programmierkenntnisse für einen Twitter Crawler?
Nein, das ist nicht nötig. Es gibt Tools wie Octoparse, mit welchen das Twitter Scraping sehr einfach ist. Möchten Sie jedoch Web Twitter Scraping mit Python, Tweepy oder Twint umsetzen? Dann benötigen Sie entsprechende Programmierkenntnisse.
Twitter scraping – Zusammenfassung
Dieses Mal haben wir eine Methode zum Twitter Scraping und Erfassen von Daten von X (Twitter) eingeführt, das unter den vielen SNS (sozialen Netzwerkdiensten) besonders viele Benutzer hat.
X-Post-Daten können Ihnen dabei helfen, Ihre Marke zu überwachen, Konkurrenten zu überwachen, ML-Modelle zu trainieren, neue Produkte zu entwickeln und vieles mehr.
X bietet auch eine API, die jedoch für Anfänger etwas schwierig zu bedienen ist, daher empfehlen wir die Verwendung eines Web-Scraping-Tools. Unter anderem ist Octoparse ein nützliches Tool, mit dem Sie Beitragsdaten ohne Code extrahieren können. Octoparse-Vorlagen enthalten bereits die X-API. Der Datenerfassungsprozess läuft schnell und effizient ab. Gleichzeitig erhalten Nutzer die nötige technische Infrastruktur für das Twitter Scraping.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



