Jameda ist mit mehr als 160.000 Arztprofilen das größte Online-Ärzteverzeichnis in Deutschland. Es enthält eine Vielzahl von Daten über Ärzte in Deutschland, wie z.B. Namen, Fachgebiete, Standorte, Bewertungen und vieles mehr. Eine Methode zur automatischen Beschaffung von Daten aus Webseiten ist Web Scraping. Dabei werden Webseiten gecrawlt und die gescrapten Daten als Excel/CSV-Datei, JSON oder in eine Datenbank wie Google Sheets exportiert. Mit Web Scraping können Sie schnell und effektiv Tausende von Arztdaten abrufen. Es ist einfach, die strukturierten Daten zu filtern, zu sortieren, zu analysieren und mit ihnen zu interagieren.
Vorteile des Scrapings von Jameda
Jameda enthält eine Fülle von strukturierten Daten zu über 160.000 Ärzten in Deutschland, einschließlich Name, Fachgebiet, Standort, Bewertungen und mehr. Jameda Scraper bietet mehrere wichtige Vorteile:
- Erhalten Sie strukturierte Daten über Ärzte – Die gescrapten Daten wurden sorgfältig geordnet und strukturiert, mit unterschiedlichen Feldern für jede Information wie Name, Fachgebiet, Adresse usw. Die Arbeit mit den Daten für Analysen und Studien wird dadurch vereinfacht.
- Erstellen von benutzerdefinierten Datenbanken – Sie können Ihre eigene benutzerdefinierte Datenbank erstellen, indem Sie die gescrapten Arztdaten exportieren. Dies gibt Ihnen die Flexibilität, die Daten nach Bedarf abzurufen, zu sortieren und zu filtern.
- Nutzung für Marketing und Forschung – Die Daten können für eine breite Palette von Marketing- und Forschungszielen genutzt werden. Sie können zum Beispiel Ärzte nach Fachgebiet und Standort für gezielte Werbekampagnen segmentieren oder Bewertungen und Rezensionen analysieren.
- Zeitersparnis gegenüber manueller Datenerfassung – Web Scraping automatisiert die Datenerfassung und spart so viel Zeit gegenüber der manuellen Extraktion von Daten aus jedem Profil.

Jameda Scraper ermöglicht, schnell und einfach große Mengen an organisierten Arztdaten für Geschäfts-, Forschungs- und Analysezwecke zu sammeln. Der Hauptvorteil besteht darin, strukturierte Daten über deutsche Ärzte zu erhalten, die manuell nur sehr mühsam zu erfassen wären.
Welche Daten kann man aus Jameda crawlen?
Einige der wichtigsten Datenfelder der Jameda-Arztprofile, die Sie extrahieren sollten, sind:
- Name – Der vollständige Name des Arztes ist entscheidend für die Identifizierung und Analyse der Daten.
- Fachgebiet – Das Fachgebiet des Arztes, z. B. Allgemeinmediziner, Kardiologe, Dermatologe, usw. Dies ermöglicht die Segmentierung und Filterung der gesammelten Daten.
- Standort – Stadt, Bundesland und vollständige Adresse, in der sich die Praxis des Arztes befindet. Ermöglicht eine geografische Analyse.
- Bewertungen & Rezensionen – Die von Patienten auf Jameda-Profilen abgegebenen Sternebewertungen und Textrezensionen. Nützlich für die Stimmungsanalyse.
- Biografie – Hintergrund, Ausbildung, Erfahrung, Fähigkeiten usw. des Arztes. Bietet zusätzlichen Kontext.
- Angebotene Dienstleistungen – Die medizinischen Dienstleistungen, Verfahren und Behandlungen, die jeder Arzt anbietet. Hilft, den Arzt auf die Bedürfnisse des Patienten abzustimmen.
- Gesprochene Sprachen – Alle Sprachen wie Englisch, Spanisch usw., in denen der Arzt mit Patienten kommunizieren kann.
- Telefonnummer – Direkte Kontaktinformationen, um die Praxis des Arztes zu erreichen.
- Website – Die URL für die persönliche Website des Arztes oder der Praxis.
Das Scraping und Extrahieren all dieser Felder in einem strukturierten Format ermöglicht eine eingehende Analyse und Nutzung der Jameda-Arztdaten für Business Intelligence und Forschungszwecke.
Das Crawlen von Jameda ist erlaubt. Daten, die auf Jameda veröffentlicht werden, können gecrawlt werden. Jameda bietet eine Fülle nützlicher Informationen. Wenn Sie nicht gut im Programmieren sind, können Sie trotzdem auf Jameda navigieren!
Drei Schritte zum Scrapen von Arztdaten mit Octoparse
Eine Methode zur Vereinfachung Ihrer Online-Datensammlung ist Web Scraping. Octoparse ist eine No-Code-Web-Scraping-Lösung für jedermann, im Gegensatz zur herkömmlichen Technik, bei der die Benutzer das Skript selbst erstellen müssen.
Sie brauchen keinen Code zu erstellen, um mit Octoparse Arztdaten in großen Mengen zu erhalten. Octoparse kann Ihnen auch beim Web-Scraping helfen und Sie sofort beraten, wie Sie einen Jameda Scraper erstellen können. Zum Beispiel kann es die Cloud-Lösung nutzen, um die Produktivität des Scrapings zu erhöhen und automatisch extrahierbare Daten für Sie zu identifizieren.
Sie können nur in drei Schritten mit Octoparse Arztdaten crawlern !
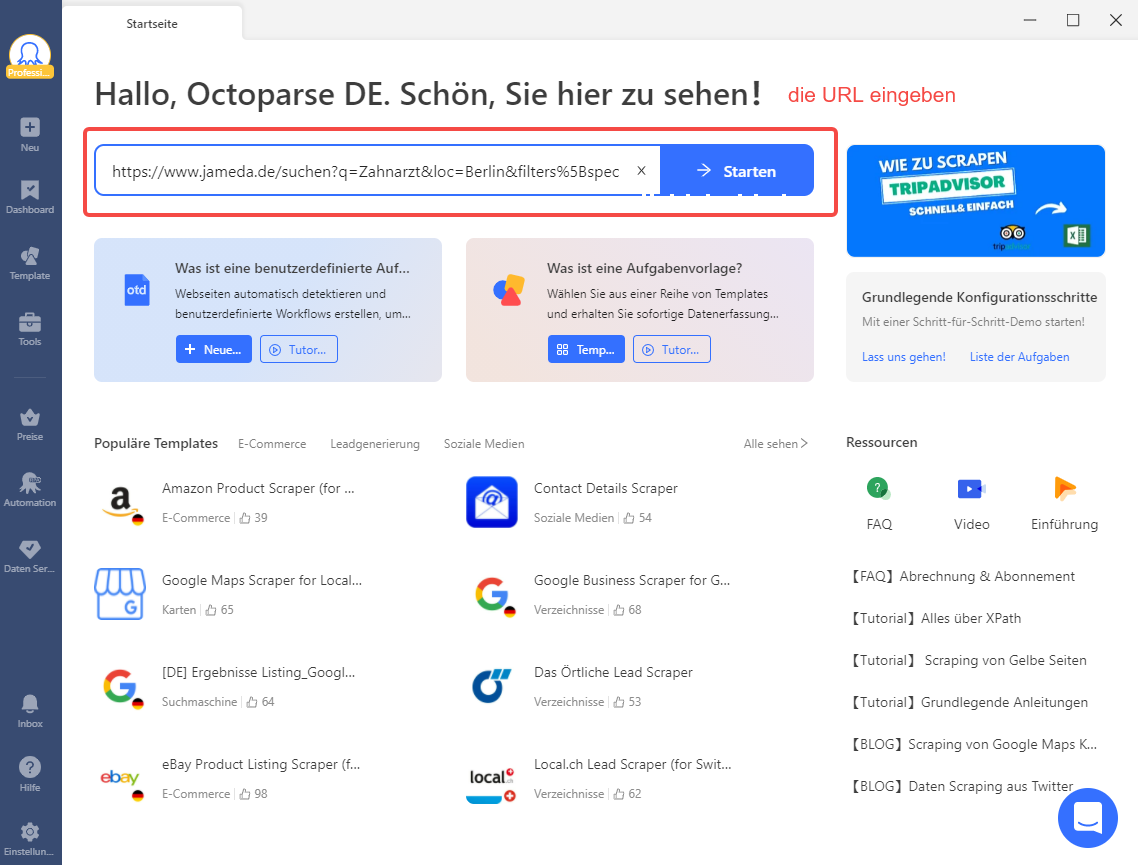
Schritt 1: Geben Sie die URL ein
Schritt 1: Laden Sie das Programm auf Ihren PC herunter und geben Sie die Ziel-URL ein, die Sie auslesen möchten. Drücken Sie dann die Schaltfläche “Starten”.
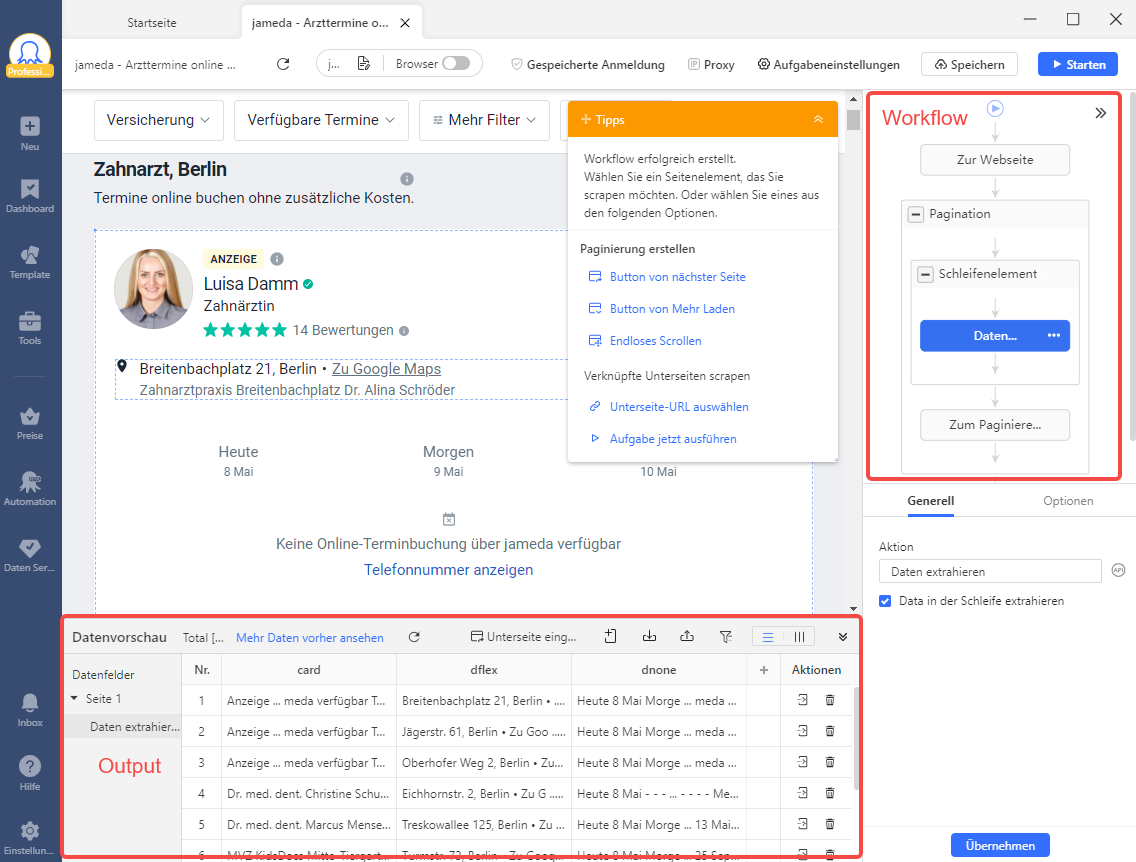
Schritt 2: Erstellen Sie automatisch einen Workflow
Eine der nützlichsten Funktionen von Octoparse ist die automatische Erkennung. Die automatische Erkennungsfunktion von Octoparse ermöglicht die automatische Erstellung von Stufen und die Änderung des Arbeitsablaufs in Übereinstimmung mit der Webseite. Dies ist sehr benutzerfreundlich für Anfänger oder Neulinge. Die Schaltfläche “Website-Daten automatisch erkennen” sollte ausgewählt werden.
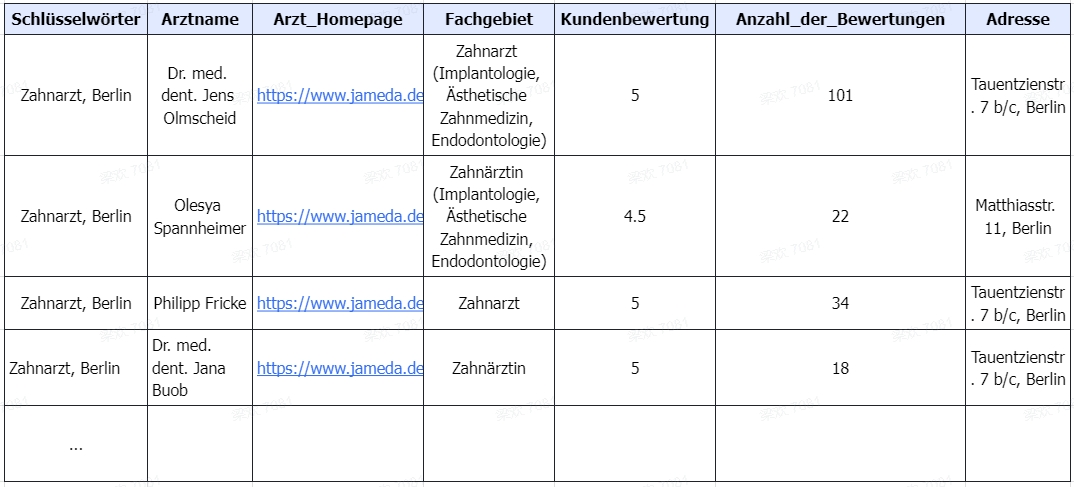
Schritt 3: Ausführen Sie die Aufgabe und exportieren Sie die Daten
Klicken Sie auf “Ausführen”, um den Scraper zu starten, nachdem Sie alle Details überprüft haben. Jetzt können Sie wählen, ob Sie die Aufgabe auf Ihrem Computer oder auf den Cloud-Servern von Octoparse ausführen möchten. Nach Abschluss der Aufgabe können Sie die gesammelten Daten als Excel/CSV-Datei, JSON oder in eine Datenbank wie Google Sheets exportieren.
Octoparse-Vorlage für Jameda
Wenn Sie nicht selbst einen Scraper konstruieren wollen, bietet Octoparse auch eine einfachere Option. Suchen Sie nach “Jameda” in der Vorlagengalerie von Octoparse. Eine Liste von vorgefertigten Vorlagen für die Extraktion von Daten aus dem lokalen System finden Sie hier. Mit nur wenigen notwendigen Eingaben können Sie mit diesen Vorlagen schnell und einfach Arztdaten sammeln. Danach können Sie in wenigen Minuten Informationen wie Name des Arztes, Fachgebiet, Anschrift, Tel., Bewertungen usw. extrahieren.
https://www.octoparse.de/template/jameda-scraper
Zusammenfassung
Mit der No-Code-Web-Scraping-Technologie von Octoparse können Nutzer ganz einfach auf Arztdaten auf Jameda zugreifen und so eine effiziente Datenerfassung ohne Programmierkenntnisse durchführen. Dieser Ansatz spart nicht nur eine Menge Zeit bei der manuellen Datenerfassung, sondern verbessert auch die Effizienz und Genauigkeit der Datenverarbeitung. Letztendlich können die Nutzer schnell ihre eigenen maßgeschneiderten Datenbanken aufbauen, um eine solide Datengrundlage für Marktanalysen, Geschäftsentscheidungen oder akademische Forschung zu schaffen.
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise: Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen: Octoparse für Windows und MacOs




