Web Scraping hat sich zu einem sehr wichtigen Hilfsmittel in sehr vielen Unternehmensbereichen entwickelt. Es gehört bei den meisten Unternehmen bereits zum Arbeitsalltag. Moderne Web-Scraper wie Octoparse sind ein wertvolles Tool, das von jedem genutzt werden kann. Und das, ohne ein zusätzliches Studium für IT absolvieren zu müssen. Mit diesem Tool können selbst Anfänger die benötigten Daten sehr leicht auslesen.
Im folgenden Beitrag zeige ich Ihnen, wie einfach es ist, ohne Kopieren und Einfügen Daten zu extrahieren. Gleichzeitig möchte ich die wichtigsten Informationen zum Web-Scraping kurz noch einmal aufzeigen bzw. in Erinnerung rufen. Web Scraping ist nicht mehr mühevoll, sondern macht Spaß.
Was bedeutet es, Daten zu extrahieren?
Daten extrahieren bedeutet, Daten von Webseiten zu sammeln und diese Daten zur weiteren Verarbeitung abzuspeichern. Ich habe zum Beispiel die Aufgabe von meinem Vorgesetzten erhalten, Informationen wie zum Beispiel über ein bestimmtes Produkt und dessen Preis von anderen Anbietern zu sammeln und zu vergleichen.
Das bedeutet für mich, ohne Web-Scraping-Tool die Webseiten der Konkurrenz zu öffnen. Das Produkt zu suchen und die benötigten Informationen zu notieren. Dabei ist die herkömmliche Methode den Namen des Anbieters, des Produktes und den Preis in einer Tabelle zu speichern. Das erfolgt mit der herkömmlichen Methode mit dem Kopieren auf der Webseite und Einfügen in die Tabelle.
Und das bei jedem Online Anbieter, der dieses Produkt vertreibt. Eine mühevolle und langwierige Arbeit, die sich über einige Tage ziehen kann. Ein Web-Scraping-Tool erledigt diese mühevolle Aufgabe innerhalb von wenigen Minuten. Zusätzlich kann das Tool die angebotenen Daten, egal ob unstrukturiert oder strukturiert, problemlos sammeln.
Strukturierte und unstrukturierte Daten
Suchen Sie im Internet bestimmte Daten, werden Sie auf strukturierte und unstrukturierte Daten stoßen. Diese Tatsache entsteht durch die unterschiedlichen Webseiten und deren Funktionen. Hier ein kurzer Überblick über die Unterschiede.
Unstrukturierte Daten:
- Befinden sich Daten in Bewertungen, Blogartikeln, Bildern und Ähnlichem und sind nicht fein säuberlich aufgelistet. Diese Daten herausfiltern und in einer Tabelle zu speichern, ist sehr mühevoll.
Strukturierte Daten:
- Dabei handelt es sich um sehr gut sortierte Informationen. Diese Infos können einfach in einer Tabelle gespeichert werden. Zum Beispiel: Preise, Produktnamen, Verkäufer, E-Mail-Adressen etc.
Damit diese Aufgabe einfacher und vor allem schneller durchgeführt werden kann, ist der Web-Scraper eine hervorragende Unterstützung.
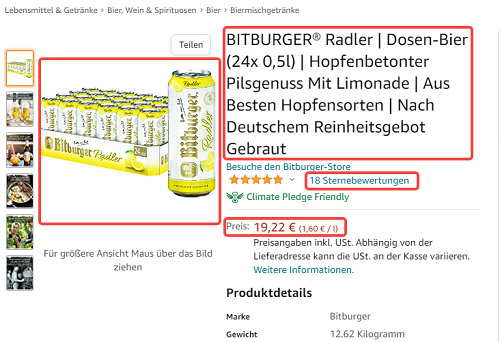
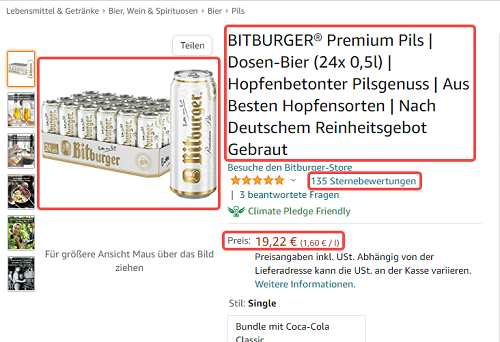
Warum werden Daten von Webseiten extrahiert?
Die Daten von Konkurrenten zu sammeln und vergleichen helfen einem Unternehmen, die eigene Strategie konkurrenzfähiger zu erstellen. Egal ob es sich um Marketing, Vertrieb oder E-Commerce handelt. Die Daten erhöhen die Vorteile im Konkurrenzkampf.
Die wichtigsten Daten im Überblick:
| Daten für die | Art der Daten | der Nutzen |
| Preisüberwachung | Aktionen, Lagerbestände und Konkurrenz-Bestände können einfacher verfolgt werden | als Händler kann man damit Preise dynamisch anpassen und den Umsatz steigern |
| Lead-Generierung | E Mails und andere Kontaktdaten werden aus Verzeichnissen oder Social Media Plattformen gesammelt | qualifizierte Leads werden einfacher gefunden und bei der Suche wird Zeit gespart |
| Wettbewerbsanalysen | die Konkurrenz, deren Angebote, Inhalte oder neue Markteinführungen können überwacht werden | es kann damit schneller auf Veränderungen reagiert werden |
| Marktforschung | News, Bewertungen, die Social Media Stimmung und weiteres können analysiert werden, um die Trends früh zu erkennen | Das Marketing kann einfacher an die Bedürfnisse der Kunden angepasst werden |
| Immobilien-Insights | Verfügbarkeiten, Preise und die Immobilienangebote können überwacht werden | damit kann ein Investor oder Makler eine Chance vor dem Markt herausfiltern |
Unternehmen in Deutschland können durch das Web-Scraping ihren Erfolg erhöhen. Der Konkurrenz damit immer einen Schritt voraus sein.
Wie funktioniert ein klassischer Web Scraper?
Ein kurzer Blick auf die klassische Scraping-Methode, die vor dem Einsatz der KI genutzt wurde. Bei dem klassischen Web Scraper handelt es sich in der Regel um Browser Erweiterungen oder Skripte. Die Skripte sind in den meisten Fällen in Python vorhanden. Damit werden die Daten ausgelesen und man kann sie in einer Tabelle speichern.
Der Ablauf erfolgt in der Regel so:
- die Datenfelder und die Zielseite wird festgelegt
- die Struktur der Webseite wird analysiert
- ein Tool auswählen, sehr gerne habe ich BeautifulSoup, Browser-Plugins oder Scrapy verwendet
- die Extraktion Logik schreiben – dabei wird dem Tool gesagt, was es zu tun hat bzw. wie Daten gefunden werden können
- hier habe ich meistens XPath oder CSS-Selektoren verwendet
- das Scraping durchführen – das Tool beginnt seitenweise die Daten zu sammeln
- die gesammelten Ergebnisse speichern – normalerweise in JSON, CSV oder direkt in einer Excel Tabelle
Hinweis: Es liest sich sicherlich einfach. Bei dem ersten Skript schleichen sich aber in den meisten Fällen Fehler ein. Eine falsche Schreibweise einer Bezeichnung ist vollkommen ausreichend, um bei einem solchen Versuch hunderte Male die Meldung “None” zu erhalten!
Typische Fallen bei der klassischen Web Scraping Methode
Bei der klassischen Methode kommt es immer wieder zu Problemen. Kleinigkeiten können dazu führen, dass der Scraper nicht funktioniert oder nur sehr langsam arbeitet.
Die häufigsten Fallen oder Probleme:
Anti-Boot-Maßnahmen:
- CAPTCHAs, Rate-Limits und IP-Sperren haben mich durch Pausen, Proxys oder der Suche nach CAPTCHA-Lösungen ausgebremst
Änderungen auf der Website:
- eine kleine Veränderung des Layouts der Website ist ausreichend, dass der Scraper keine Daten sammeln, kann
- Änderungen auf Webseiten können dazu führen, dass der Scraper kaputt wird
Unsaubere Daten:
- ich habe endlos Zeit vergeudet um Formate “aufzuräumen”, komische Codierungen oder fehlende Werte zu suchen
Das technische Wissen:
- man muss die Programmierungssprache verstehen und programmieren können
Die Wartung:
- damit der Scraper einwandfreie Ergebnisse liefern kann muss er regelmäßig ein Update erhalten und gepflegt werden
Anfänger haben damit sicherlich Probleme und fühlen sich überfordert. Ich vergleiche diesen Prozess gerne mit einem Kochrezept, das sich laufend verändert.
Die modernen KI Web Scraper – einfacher geht Daten extrahieren eigentlich nicht
Octoparse zählt zu den modernen Web-Scrapern. Es müssen hier keine Selektoren gebastelt und auch kein Code geschrieben werden. Einfach in die vorgegebenen Felder schreiben was benötigt wird und schon geht es los.
Drei Schritte sind bei Octoparse ausreichend, um Daten rasch extrahieren zu können. Ich zeige Ihnen hier die drei einfachen Schritte, um rasch an die gewünschten Ergebnisse zu kommen.
So geht Daten extrahieren mit Octoparse:
1. Octoparse aufrufen, den Download durchführen und registrieren

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
2. Octoparse bietet bereits fertige Vorlagen, um das Extrahieren der Daten noch einfacher zu machen. Vorlage suchen und die URL der Webseite eingeben. Das Scraping starten und auf die Ergebnisse warten. Über den Vorschaumodus kann die Suche überwacht werden. Über ein Datenfeld am oberen rechten Rand kann die Suche falls notwendig angepasst werden.
https://www.octoparse.de/template/email-social-media-scraper
3. Wurden die gesuchten Daten geliefert, können sie mit dem Klick auf “Exportieren” einfach in die gewünschte Datei gespeichert werden. Zum Beispiel eine Excel Datei oder Ähnliches.
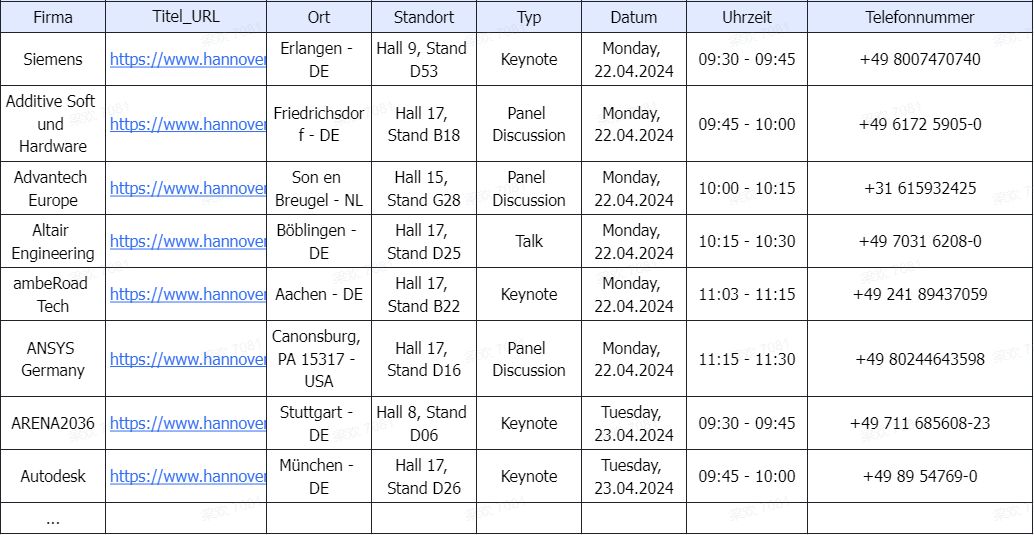
Tipp: Ich nutze gerne den “Advanced Mode” bei Octoparse. Mit diesem nützlichen Helfer kann man sehr leicht selbst einen Crawler einrichten. Die angebotenen Vorlagen machen es möglich, ohne weitere Aufgaben-Konfigurationen die erforderlichen Daten auszulesen.
Tipps um Fehler beim Daten extrahieren zu vermeiden
Das Daten extrahieren mit Octoparse ist sehr einfach. Trotzdem kann es passieren, dass man Fehler macht. Die folgenden Tipps helfen Ihnen dabei, Fehler zu vermeiden. Die Nutzungsbedingungen der Webseite vorher lesen – in den Nutzungsbedingungen steht, ob das Daten-Scraping erlaubt ist. Außerdem muss darauf geachtet werden, dass sensible Daten nicht extrahiert werden. Eine Webseite durch das Extrahieren nicht überlasten – extrahiert man Daten mit einem klassischen Tool ist es empfehlenswert Pausen einzulegen.
Sich auf Änderungen vorbereiten – eine Webseite kann sich laufend verändern. Octoparse passt sich hier sehr gut an. Es ist trotzdem gut, wenn man bei größeren Änderungen ein bisschen Acht gibt. Daten immer kontrollieren – Stichproben zwischendurch helfen dabei, dass das Ergebnis später korrekt ist. Immer die Ethik berücksichtigen – immer nur die notwendigen Daten extrahieren und bei einer eventuellen Veröffentlichung die Quelle nennen.
Fazit
Betrachtet man die Entwicklung des Web Scraping, so war diese bisher sehr rasant. Von handschriftlich angelegten Skripten bis zu den Tools mit KI Unterstützung ist nicht sehr viel Zeit vergangen. Und die KI unterstützten Tools können auch von Beginnern einfach genutzt werden. Man benötigt keine Ausbildung als Programmierer.
Einfach ein hilfreiches Tool einsetzen und die benötigten Daten werden im Handumdrehen extrahiert. Die angebotenen Tools wie zum Beispiel Octoparse sind extrem einfach anzuwenden. Ersparen Sie sich das mühevolle Kopieren und Einfügen. Der Web Scraper übernimmt diese Aufgabe zuverlässig in wenigen Minuten. Sie müssen nur den Scraper ein bisschen beaufsichtigen.
FAQs
Kann man Daten von Webseiten mit JavaScript extrahieren
Bei JavaScript-lastigen Webseiten eignen sich hervorragend Scraping Tools, die das dynamische Rendering beinhalten. Die KI unterstützen Scraper wie zum Beispiel Octoparse, simulieren das menschliche Verhalten und können dadurch Javascript extrahieren.
Ist es möglich, eine Webseite mit einem Login zu scrapen?
Eine Webseite mit Login zu scrapen ist sehr aufwendig. Zudem kann es gegen die Richtlinien der Webseite verstoßen, von dieser Seite Daten auszulesen. Bevor man in diesem Fall ein spezielles Tool nutzt, sollte die rechtliche Sachlage geklärt werden.
Kann man verhindern, dass man beim Scraping blockiert wird?
Damit ich beim Scraping nicht blockiert werde, arbeite ich mit Rate Limiting. Zusätzlich mehrere Pausen einlegen und nicht zu aggressives Scraping reduziert ebenfalls das Risiko einer Sperre. Web Scraper mit KI übernehmen diese Maßnahmen selbständig.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬



