Während uns die Informationsexplosion mehr Chance zu Ressourcen, Inhalten und Meinungen angeboten hat, raten wir dabei in die Wirrung, darin haben wir als Empfänger*in keine Ahnung, welche Informationen richtig und uns selbst wichtig sind. In diesem Fall sind wir keine Rationale, sondern haben wir das Denkvermögen verloren, sind wir von allen echten und falschen Informationen beeinflusst. Deswegen ist es uns sehr dringend zu erlernen, die Informationen von Höhe und Ganze zu beobachten und analysieren, indem wir selbständig deken können.
Zu disem Zweck bräucht man normalerweise ein Weckzeug, wie z. B. Webscraper, um die Informationen schnell und rechtzeitig zu sammeln. Wenn Sie nicht wissen, wie man die Informationen aus vielseitigen Nachrichten scrapen kann, oder wissen Sie schon aber wenige Programmierungskenntnisse beherrschen, lesen Sie bitte diesem Artike, darin sind TOP 3 Artikel Scraper von Nachrichten und Blogs vorgestellt und ein Scraper für Medium als Beispiel genommen.
Octoparse
Als eines der besten kostenlosen automatischen Web-Scraping-Tools ist Octoparse für Programmierer und Nicht-Programmierer entwickelt, um komplizierte Web-Scraping-Aufgaben zu bewältigen. Es kann menschliches Surfverhalten nachahmen und Artikel von jeder Website innerhalb von Minuten auslesen.
Mit Octoparse stehen Ihnen über 100 benutzerfreundliche Vorlagen zur Verfügung, um Daten schnell und einfach zu extrahieren. Darüber hinaus ermöglicht Ihnen die Octoparse-Vorlage die gezielte Extraktion der gewünschten Daten auf einfache Weise. Die Benutzerfreundlichkeit der Octoparse-Vorlage ist besonders hervorzuheben!
https://www.octoparse.de/template/gelbe-seiten-scraper
Point & Click Interface
Octoparse kommt mit einer benutzerfreundlichen UI. Es ermöglicht Ihnen, die Interaktion mit Ihren bevorzugten Websites in seinem intergrierten Browser mit Point-und-Click-Aktionen zu verwirklichen.
Erweiterte Funktionen
Mit vielen leistungsstarken Funktionen hilft Octoparse Ihnen bei der Erleichterung des Artikel Scrapings, wie z.B. bei dem unendlichen Scrollen der Website, dem Behalten des Einloggen-Status und der Suche nach Stichwörter.
Cross-Plattform
Bei der Verwendung von Octoparse findet man es sehr günstig, dass Octoparse nicht nur mit Windows sondern auch mit Mac OS kompatibel ist. Sie können Octoparse einfach von octoparse.de herunterladen und die zu Hande nehmenden Vorlagen für Artikel Scraping. Vor dem Versuch können Sie zuerst die Tutorials durchschauen und dann einen Crawler erstellen.
Acceleration & Scheduling
Octoparse verfügt über einen Boost-Modus, der die Geschwindigkeit des Artikel-Scrapings sowohl auf lokalen Geräten als auch in der Cloud erheblich verbessert. Wenn Sie schnell und einfach aktuelle Artikel auslesen möchten, können Sie einen Scraper nach Ihrem Zeitplan wöchentlich täglich sogar stündlich einstellen.
Kundenservice
Das Octoparse-Team bietet auch einen hervorragenden Kundensupport und ist bestrebt, Ihnen bei allen Arten von Datenanforderungen zu helfen. Wenn die vorhandenen Vorlagen Ihre Wünsche nicht erfüllen, kann das Team auch nach Ihren Datenerfordeungen einen kundenspezifischen Daten Scraper entwickeln.
Zahlreiche Templates
Octoparse bietet über 100 benutzerfreundliche Vorlagen, um Daten zu extrahieren. Über 30.000 Nutzer verwenden die Vorlagen
https://www.octoparse.de/template/email-social-media-scraper
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise: Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen: Octoparse für Windows und MacOs
WebHarvy
WebHarvy ist eine weitere kundenorientierte Artikel Scraping-Software, aber erfordert Windows-Betriebssystem. Es kann verwendet werden, um Artikelverzeichnisse und Pressemitteilungen von PR-Websites zu durchsuchen.
Einfache Erklärungsserie
Sie können die Erklärvideos auf der offiziellen Website von WebHarvy ansehen, wie Sie eine Aufgabe erstellen können, um den Titel, den Namen des Autors, das Veröffentlichungsdatum, Schlüsselwörter und den Haupttext eines Artikels zu scrapen. Wenn Sie neu im Web Scraping sind, könnten sie ein guter Ausgangspunkt sein.
Evaluation Verison
Es wird sehr empfohlen, die Testversion herunterzuladen und die grundlegenden Tutorial-Videos anzusehen, um Ihre Datenreise zu starten. Es ist sehr einfach zu bedienen und unterstützt auch Proxies und geplantes Scraping. Wenn es Ihre Datenanforderungen erfüllen kann, können Sie Single User License von WebHarvy für nur 139 USD erwerben.
ScrapeBox
Als eines der leistungsfähigsten und beliebtesten SEO-Tools hat ScrapeBox ein Artikel-Scraper-Addon, mit dem Sie Tausende von Artikeln aus einer Rihe beliebter Artikelverzeichnisse ernten können.
Lightweight Add-on
Als leichtgewichtiges Addon bietet das Artikel-Scraper-Addon von ScrapeBox:
- Proxy-Unterstützung
- Multithreading für schnelles Abrufen von Artikeln
- Rechungsfähigkeit für die gesamtliche Anzahl der gescrapten Artikeln.
- Datenspeicherung in ANSI, UTF-8 oder Unicode-Format.
Keyword-based Filter
Mit ScrapeBox kann man auch die Links und E-Mail-Adressen automatisch aus Artikeln entfernen lassen. Die abgerufenen Artikeln können auch nach den Stichwörter kategorisiert werden.
Medium als Beispiel
Um besser zu erklären, wie ein Artikel Scraper funktioniert, werden wir die Artikeln aus Medium mit Octoparse scrapen. Als Beispiel wird die URL von Medium genommen: https://medium.com/towards-data-science
Schritt 1 Öffnen Sie die Ziel-Website mit Octoparse
Jeder Workflow in Octoparse beginnt mit der Eingabe einer Webseite. Geben Sie einfach die Beispiel-URL in die Suchleiste auf dem Startbildschirm ein und warten Sie, bis die Webseite angezeigt wird.
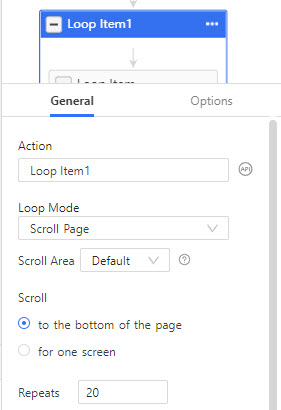
Schritt 2 Fügen Sie ein “Page Scroll Loop hinzu”
Mit einem Loop für Page Scroll wird die Website automatisch nach unten gescrollt, bis alle Inhalte auf der Seite von Octoparse völlig erkennt werden. Dazu wählen Sie Scroll Page im Rahmen von Loop Item und stellen Sie den Wert von Repeats zu 20 ein.
Schritt 3 Scrapen die Daten von der Artikellistenseite
Bevor wir den Inhalt jedes Artikels sammeln, müssen wir einige Metadaten von der Listenseite sammeln.
- Klicken Sie auf den ersten Artikelblock in der Liste und wählen Sie “Select sub-elements” > “Select All” > “Extract data”, um die Daten aus der Artikelliste zu sammeln.
- Benennen Sie die Datenfelder um und löschen Sie unerwünschte Datenfeldern.
- Darüber hinaus können wir die Artikel-URLs mit dem XPath-Locator erfassen.
- Klicken Sie “add a custom field” im “Data Preview” und wählen Sie “Capture data on the webpage”.
- Wählen Sie Relative XPath und geben Sie //a [@aria-label=”Titel der Beitragsvorschau”]
- Klicken Sie dann “Save and Run”.
Schritt 4 Verwenden Sie die URL-Liste für eine zweite Aufgabe, um Volltext zu scrapen
Als nächstes müssen Sie eine untergeordnete Aufgabe mit den URLs aus dem letzten Datenlauf erstellen.
- Gehen Sie zurück zum Octoparse-Startbildschirm, klicken Sie auf “+ New” und wählen Sie “Advanced Mode”.
- Geben Sie die von der ersten Aufgeben eingebenen URLs ein und erstellen einen Workflow von “URL-Loop”.
- Fügen Sie einen Worflow unter “URL-Loop” duch “Extract data” hinzu.
- Klicken Sie dann “add a custom field” im “Data Preview” und wählen die gewünschten Datenfeldern auf der Seiten.
- Klicken Sie “Absolute XPath” und geben XPath: //article ein.
Schritt 5 Speichern und Ausführen der Aufgabe, um die Daten zu erhalten
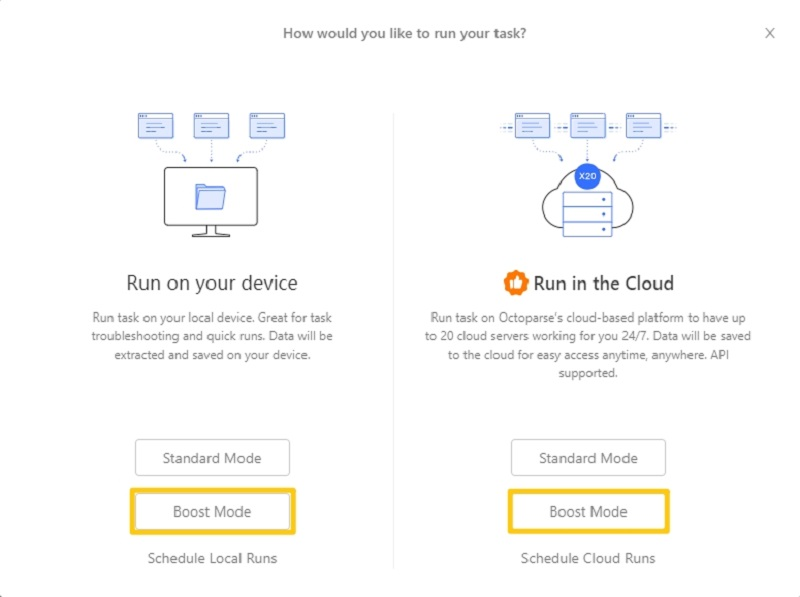
Sie haben vielleicht bemerkt, dass wir die Aufgabe in zwei Teilaufgaben unterteilt haben. Es ist beabsichtigt, die Scrapingsgeschwindigkeit des gesamten Aufgabe zu erhöhen. Wenn Sie eine komplizierte Aufgabe handeln müssen, empfiehlt es sich, die Aufgabe aufzuteilen und sie in der Cloud-basierten Plattform von Octoparse auszuführen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



