In diesem Artikel geht es nicht um das Kinderspiel Duck, Duck, Goose, sondern um eine Internetsuchmaschine, deren Name eine Anspielung auf dieses berühmte Spiel ist.
DuckDuckGo unterscheidet sich von anderen Suchmaschinen wie Google und Microsoft Bing durch seine eigene Positionierung auf dem Markt. Während diese Suchmaschinen einen Algorithmus verwenden, um personalisierte Suchergebnisse zu liefern, setzt DuckDuckGo auf den Schutz der Privatsphäre der Nutzer und die Vermeidung von Filterblasen. Dies wird erreicht, indem verschiedene APIs anderer Websites genutzt werden, um schnelle und relevante Ergebnisse zu liefern, anstatt auf Inhalte von Content-Farmen zurückzugreifen. Laut der offiziellen Website verzeichnet DuckDuckGo etwa 3 Milliarden monatliche Suchanfragen und 6 Millionen monatliche Downloads.
Hier finden Sie die einfachen Schritte zum Scrapen von DuckDuckGo-Suchergebnissen und zum Exportieren in Excel-Dateien.
Was Sie über DuckDuckGo Web Scraping wissen müssen
Ist es legal, DuckDuckGo zu scrapen?
Es ist in der Regel akzeptabel, Web-Scraping zu betreiben, solange dabei keine privaten Informationen gestohlen werden. Es kann jedoch vorkommen, dass das Extrahieren von Daten von einer Website gegen deren Nutzungsbedingungen verstößt. Obwohl ein Verstoß gegen die Nutzungsbedingungen nicht illegal ist, könnte die Website rechtliche Schritte wegen Vertragsbruchs gegen Sie einleiten. Um solche unangenehmen Situationen zu vermeiden, empfehlen wir dringend, die Nutzungsbedingungen zu lesen, bevor Sie mit dem Scrapen beginnen.
Hat DuckDuckGo APIs?
Ja, DuckDuckGo ermutigt seine Nutzer, seine offiziellen APIs zu nutzen. Zuvor bot DuckDuckGo eine Instant Answer API an, die jedoch nicht alle Links in den Suchergebnissen enthielt. Derzeit gibt es keine weiteren Details zu den verfügbaren APIs auf DuckDuckGo. Wenn Sie mehr erfahren möchten, sollten Sie die Hilfeseite sorgfältig lesen oder sich über die offizielle Seite mit den Entwicklern in Verbindung setzen.
4 Schritte zum Scrapen von DuckDuckGo-Suchergebnissen
Anstelle von APIs zeigen wir Ihnen, wie Sie Suchergebnisse von DuckDuckGo mit Octoparse extrahieren können. Es ist ein einfach zu bedienendes Tool für Web Scraping. Jeder Benutzer kann damit vollständige Suchergebnisse von DuckDuckGo sammeln, unabhängig von seinen Programmierkenntnissen.
Beim ersten Gebrauch können Sie Octoparse herunterladen und auf Ihrem Gerät installieren. Sie müssen sich anmelden, um die App zu starten, und ein kostenloses Konto erstellen. Nach erfolgreicher Anmeldung können Sie die folgenden Schritte ausführen, um DuckDuckGo-Suchergebnisse 14 Tage lang kostenlos zu scrapen!
Schritt 1: Erstellen Sie eine neue Aufgabe
Kopieren Sie die URL der Suchergebnisseite und fügen Sie sie in die Suchleiste von Octoparse ein. Klicken dann auf „Starten“, um eine neue Aufgabe zu erstellen. Die Zielseite wird in Sekundenschnelle in den integrierten Browser von Octoparse geladen.
Schritt 2: Wählen Sie die gewünschten Datenfelder aus
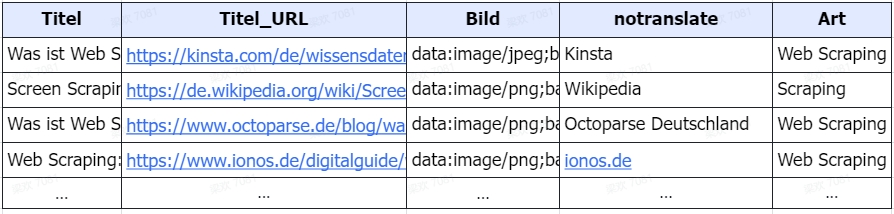
Nachdem die Seite vollständig geladen ist, klicken Sie auf “Webpage-Daten automatisch erkennen” in den Tipps. Dadurch wird Octoparse die Website scannen und Ihnen verschiedene Datenvorschläge anbieten. Die erkannten Datenfelder werden auf der Seite hervorgehoben, damit Sie überprüfen können, ob Octoparse richtig liegt. Sie können die Daten auch unten in der Vorschau anzeigen und unerwünschte Datenfelder entfernen.
Schritt 3: Erstellen und Ändern des Workflows
Sobald Sie alle erforderlichen Datenfelder ausgewählt haben, klicken Sie auf “Workflow erstellen”. Daraufhin wird auf der rechten Seite des Bildschirms ein Workflow angezeigt, der jeden Schritt des Scraping-Prozesses darstellt. Sie können den Workflow von oben nach unten und von innen nach außen in verschachtelten Aktionen lesen. Um sicherzustellen, dass alles ordnungsgemäß funktioniert, können Sie jeden Schritt in der Vorschau anzeigen, indem Sie auf die einzelnen Stufen klicken. Wenn der Workflow nicht ordnungsgemäß funktioniert, kann es sein, dass keine Daten erhalten werden.
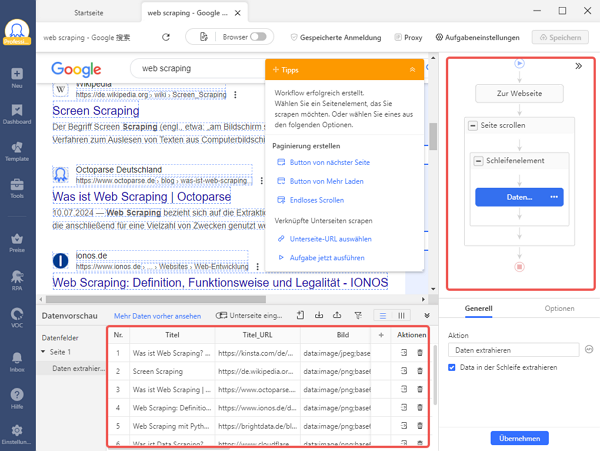
Schritt 4: Starten Sie die Aufgabe
Bitte klicken Sie auf „Ausführen“, um den Scraper zu starten, nachdem Sie alle Details überprüft haben. Es gibt zwei Möglichkeiten, die Aufgabe auszuführen. Wenn Ihr Projekt klein ist oder Sie nur einen schnellen Durchlauf benötigen, können Sie es auf Ihrem lokalen Gerät ausführen. Für große Projekte ist es jedoch besser, die Aufgabe auf die Cloud-Server von Octoparse zu übertragen. Wählen Sie einfach eine Option, und Octoparse kümmert sich um den Rest. Nach Abschluss der Aufgabe können Sie die Daten in eine Excel-, CSV- oder JSON-Datei exportieren.
Einen DuckDuckGo-Crawler mit Python erstellen
Wenn Sie mit Python vertraut sind, ist die Erstellung eines Crawlers eine großartige Möglichkeit, um Daten von DuckDuckGo zu sammeln, ohne die offizielle API zu verwenden. Im folgenden Beispiel finden Sie einen Code, den Sie als Referenz für die Erstellung Ihres eigenen DuckDuckGo-Crawlers verwenden können.
Vorlagen – Der einfachste Weg, DuckDuckGo zu scrapen
Um Ihre Web-Scraping-Reise zeitsparender und müheloser zu gestalten, bietet Octoparse jetzt Hunderte von Vorlagen, mit denen Sie Daten von verschiedenen Websites ohne Einstellungen scrapen können. Beim Scrapen von DuckDuckGo-Suchergebnissen mit der untenstehenden Vorlage musst du nur die Suchbegriffe (bis zu 10k pro Durchlauf) eingeben, die du auf DuckDuckGo suchen möchtest. Danach kümmert sich Octoparse um den Rest und versorgt Sie mit aktuellen Informationen, einschließlich Titel, Ergebnis-URL, Hauptseite und Beschreibung.
https://www.octoparse.de/template/duckduckgo-scraper
Zusammenfassung
DuckDuckGo wächst schnell und bietet offizielle APIs an, aber es gibt auch alternative Lösungen. In unserem Artikel zeigen wir, wie man Suchergebnisse mit Octoparse scrapen oder einen Crawler mit Python erstellen kann. Egal, ob Sie programmieren können oder nicht, Sie finden hier eine Methode, um Ihr Ziel des Web Scraping zu erreichen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise: Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen: Octoparse für Windows und MacOs




