IMDb, die Abkürzung für Internet Movie Database, ist eine beliebte Online-Datenbank, die Informationen über Filme, Fernsehsendungen, Heimvideos, Videospiele und mehr enthält. Im März 2022 umfasste diese Website etwa 10 Millionen Titel und 11,5 Millionen menschliche Datensätze.
IMDb ist ein idealer Ort für alle, die sich für digitale Werke interessieren, den Trend kennenlernen und Informationen für eine tiefer gehende Analyse sammeln wollen. Und mit Web-Scraping-Tools kann die riesige Menge an Filmdaten auf IMDb auch in strukturierte Datendateien übertragen werden. In den folgenden Abschnitten erfahren Sie, wie Sie ganz einfach Daten aus IMDb scrapen können.
Was ist ein Movie-Scraper?
Scraper werden verwendet, um die Informationen auf der Seite zu scrapen. Movie-Scraper bedeutet, dass Metadaten für Video- und Musikelemente herunterzuladen sind. Eigentlich ist Movie-Scraper eine Form von Web Scraping oder Web Crawler.
Ist es legal, IMDb zu scrapen?
Im Allgemeinen ist Web Scraping legal. Aber einige Plattformen haben möglicherweise detailliertere Regeln in diesem Bereich. Sie müssen diese bestimmten Vorschriften einhalten, bevor Sie Daten auslesen. IMDb erlaubt seinen Nutzern auch, seine Inhalte für nicht-personenbezogene Zwecke zu verwenden. Sie können die Nutzungsbedingungen von IMDb besuchen, um weitere Einzelheiten zu erfahren.
Dennoch ist es wichtig, dass Sie auf Ihre Datennutzung und die Gesetze oder Vorschriften Ihres Landes achten. Während zum Beispiel kleine Mengen von Scraping für persönliche, nicht-kommerzielle Zwecke manchmal übersehen werden, ist umfangreiches oder kommerzielles Scraping von IMDb-Daten ohne ausdrückliche Genehmigung verboten. Und das Urheberrecht einiger Filme/Fernsehsendungen ist manchmal selbst nicht erlaubt.
Hat IMDb eine API?
IMDb bietet jetzt vier verschiedene APIs an. Jede von ihnen dient dazu, verschiedene IMDb-Daten zu sammeln, z. B. Titel, Darsteller, Schöpfer, Einschaltquoten, Einspielergebnisse auf Lebenszeit usw. Diese APIs sind vollständig vorgefertigt und erlauben es den Nutzern nicht, sie nach ihren eigenen Bedürfnissen zu verändern.
Außerdem sind sie recht teuer. Sie können sie auf dem AWS-Marktplatz ausprobieren. IMDb bietet auch eine kostenlose Testversion für ein einmonatiges Abonnement an, wenn Sie nicht sicher sind, ob Sie viel Geld dafür ausgeben möchten.
Was wird von Movie-Scraper erhalten?
Ein Movie-Scraper könnte Ihnen helfen, diese Daten wie folgend zu scrapen:
- Titeldetails – Grundlegende Informationen über Filme und Fernsehsendungen wie Titel, Jahr, Genre, Laufzeit, Bewertungen, Zusammenfassung der Handlung usw.
- Cast & Crew – Vollständige Listen von Schauspielern, Regisseuren, Produzenten und ihren jeweiligen Rollen/Arbeitsplätzen für einen Titel.
- Biographien – Detaillierte Profile und Biographien von Schauspielern, Regisseuren und Produzenten mit Fotos, Filmographien usw.
- Bilder – Hochauflösende Plakatbilder und Fotos zu den Titeln, Darstellern und der Crew. Unterliegt zusätzlichen Lizenzbedingungen.
- Unternehmen – Profile von Film-/TV-Produktionsstudios und Unternehmen.
- Veröffentlichungstermine – Nationale und internationale Veröffentlichungstermine für Filme/Episoden.
- Auszeichnungen & Nominierungen – Wichtige gewonnene/nominierte Auszeichnungen, sortiert nach Jahr.
- Benutzerbewertungen und -rezensionen – Von IMDb-Benutzern abgegebene Bewertungen und Rezensionen.
- Weitere Informationen wie Veröffentlichungstermine, Einspielergebnisse, Musik, Jugendschutzhinweise usw.
Sie können auch andere Daten wie Bewertung der Filme oder Informationen zu Fernsehsendungen extrahieren, solange sie auf der Webseite vorhanden sind. Sie können Ihren Scraper so inpiduell einrichten, dass Sie alle gewünschten Daten erhalten, sobald Sie den Dreh raus haben.
Vorteile des Scraping von IMDb
Das Scraping von IMDb-Daten ermöglicht es Ihnen, die schmutzigen Daten in strukturierte Datendateien umzuwandeln und zur weiteren Analyse und Forschung beizutragen. Hier sind einige Vorteile der Sammlung von IMDb-Daten:
Marktforschung betreiben
Für Menschen, die in der Filmbranche tätig sind, sind IMDb-Daten eine große Hilfe, um den Markt zu verstehen. Wenn Sie IMDb-Daten in ein strukturiertes Format bringen und eine schnelle Datenbereinigung durchführen, können Sie leicht herausfinden, welches Genre auf dem Markt am beliebtesten ist, welche Art von Filmen die höchsten Einspielergebnisse erzielt hat, wer der große Star in der Branche ist usw.
Sentimentale Analyse durchführen
IMDb hat bisher über 83 Millionen registrierte Nutzer. Sie geben wertvolle Kritiken zu Millionen von Werken ab und bewerten sie. Auch diese Informationen sind auf IMDb extrahierbar. Sie können den Text der Kritiken auslesen und eine Textanalyse durchführen, um ein Gefühl dafür zu bekommen, wie sehr das Publikum einen Film liebt oder hasst, wie sehr es sich von bestimmten Werken angesprochen fühlt und sogar, ob das Publikum die Leistung der Schauspieler mag.
Erstellen Sie eine persönliche Datenbank
Eine persönliche Datenbank wird häufig verwendet, um häufig genutzte Informationen zu speichern. Wenn Sie Zugang zu genügend IMDb-Daten haben, können Sie versuchen, selbst eine zu erstellen. Das spart Zeit bei der Verwaltung der Daten. Sie können die Daten so strukturieren, wie Sie es wünschen, und so die Qualität und Konsistenz der Informationen verbessern. Sie könnten dadurch produktiver werden!
Wie man Filmdaten von IMDb abruft
Wenn Sie mit der Programmierung nicht vertraut sind, können Sie Daten mit einem Web Scraping Tool extrahieren. Octoparse ist ein solches Web-Scraping-Tool, für das keine Programmierkenntnisse erforderlich sind. Mit seiner einfachen automatischen Erkennungsfunktion und voreingestellten Vorlagen können Sie fast alle Websites mit wenigen Klicks scrapen.
Um Ihnen bei der Datenerfassung zu helfen, wird dieser Artikel Sie durch einen Web-Scraping-Fall führen, um die Informationen aus der IMDb-Filmliste – IMDb Top 250 Movies – zu scrapen.
Wir werden mit den grundlegenden Informationen beginnen: Filmname, Jahr, URLs der vorgestellten Seiten, Titelbild und Kundenbewertungen.
(Wenn Sie die Technik beherrschen, können Sie die erweiterte Suche verwenden, um die Filme herauszufiltern, die Sie interessieren und die Liste der Daten ganz nach unten erhalten.)
Alles klar, jetzt werden wir diesen Link verwenden, um die 250 besten Filme auf IMDb zu finden:
Wenn Sie zunächst einige Grundlagen dieses Movie Scrapers lernen möchten, finden Sie hier eine kleine Einführung: die grundlegende Logik der Verwendung von Octoparse.
Wenn Sie sich nicht die Mühe machen wollen, irgendetwas zu lesen, dann können Sie noch in dieses Tutorial bleiben, weil diese Anleitung ganz einfach zu befolgen ist. Tatsächlich gibt es nicht mehr als ein paar Schritte.
Scraping von Top 350 Filmen in 30 Sekunden
Dies ist ein Schritt-für-Schritt-Tutorial zur Datenextraktion von IMDb-Film mit dem automatischen Erkennungsmodus von Octoparse.
Ein kurzer Blick auf die Anleitung:
Schritt 1: Öffnen Sie die Zielseite im intergrierten Browser von Octoparse.
Schritt 2: Klicken Sie auf „Auto-detect web page data“.
Schritt 3: Wählen Sie den Datensazt, den Sie scrapen möchten, dann klicken Sie auf „Create workflow“ zu bestätigen.
Schritt 4: Nachdem der Workflow eingerichtet ist, klicken Sie auf „Run“ zur Durchführung des Workflows.
Schritt 5: Exportieren Sie die Daten für die Offline-Verwendung.
Schritt 1: Öffnen Sie die Zielseite im intergrierten Browser von Octoparse.
Geben Sie auf der Startseite einfach die URL in der Suchleiste ein und klicken Sie auf „Enter“. Der integrierte Browser beginnt, die Seite zu rendern.

Schritt 2: Klicken Sie auf „Auto-detect web page data“.
Sobald die URL erfolgreich im integrierten Octoparse-Browser gerendert wurde, würden Sie eine gelbe Tips-Platte sehen. Es gibt dort einige Optionen, um Ihnen die Vorschläge zu geben, was Sie für den nächsten Schritt tun sollen.
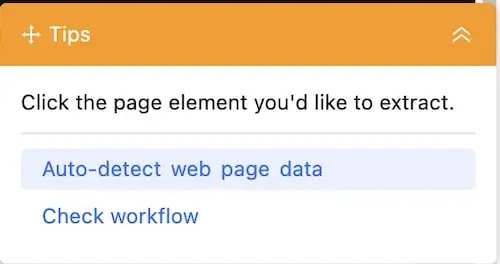
Klicken Sie an dieser Stelle auf die Option „Auto-detect web page data“ und Octoparse wird die Seite umfassend und detailliert scannen.
Schritt 3: Wählen Sie den Datensazt, den Sie scrapen möchten, dann klicken Sie auf „Create workflow“ zu bestätigen.
Sobald die automatische Erkennung abgeschlossen ist, teilt Octoparse Ihnen mit, was es auf der Seite gefunden hat, das sehr wahrscheinlich dem entspricht, was Sie suchen. Und es kann mehr als ein Datenergebnis zur Auswahl stehen.
Schauen Sie auf der Benutzeroberfläche nach unten. In der Vorschaubox sehen Sie jetzt das erste Ergebnis der Empfehlungsdaten. Woohoo, das ist ein perfektes Formular mit genau den Daten, die wir extrahieren wollen.

Wenn Sie zu einem anderen Ergebnis wechseln möchten, um zu prüfen, was Octoparse Ihnen anbietet, klicken Sie auf „Switch auto detect results“, um Ihre Neugierde zu befriedigen. Sobald Sie Ihre Entscheidung getroffen haben, klicken Sie auf „Create Workflow“, um Ihre Wahl zu bestätigen.
Schritt 4: Nachdem der Workflow eingerichtet ist, klicken Sie auf „Run“ zur Durchführung des Workflows.
Nachdem Sie auf „Create workflow“ geklickt haben, werden Sie einige Änderungen auf der Benutzeroberfläche sehen und auf der rechten Seite erscheint ein sogenannter Workflow Ihres Movie Scrapers.
Dabei geht es um einige Befehle und Regeln, die Sie für die Ausführung des Scrapers festlegen. In diesem Fall hat Octoparse mit seinem intelligenten Algorithmus die automatische Erkennung für Sie eingerichtet. Sie können lernen, wie Sie selbst einen Workflow aufbauen, um später einen inpiduelleren Scraper zu erstellen.
Auf jeden Fall haben wir schon es bekommen, was wir wollten. Und nun klicken wir oben rechts auf die kleine blaue Schaltfläche „Run“, um den Scraper zu starten. Wenn Sie mit Octoparse kostenlos starten, wählen Sie die Ausführung auf Ihrem lokalen Gerät.
Tipps!
Durchführung in der Cloud ist schneller und kann auch es vermeiden, blockiert zu werden. Klicken Sie hier, um mehrere Vorteile über Cloud-Datenextraktion zu erfahren.
Ich bekomme meine Daten nur in 30 Sekunden. Web Scraping ist so erstaunlich!
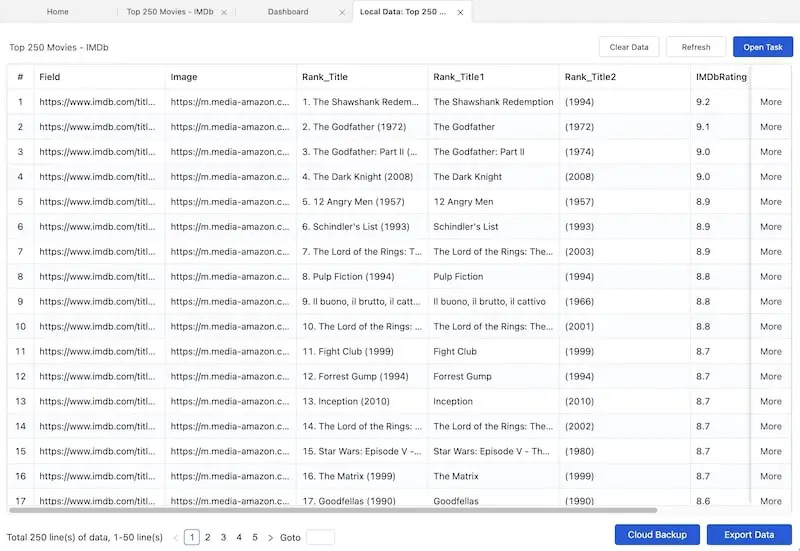
Schritt 5: Exportieren Sie die Daten für die Offline-Verwendung.
Sie haben sicher schon erlebt, wie schnell ein Web Scraper Daten aus dem Internet kopieren kann. Da die Daten gut geordnet und heruntergeladen sind, können Sie sie in Formate wie Excel, CSV, HTML oder JSON exportieren.
Wir haben es geschafft! So ein intelligenter IMDb Film Scraper. Auf die gleiche Weise können wir einen Flixster Film Scraper, Rotten Tomatoes Filmbewertung Scraper und Netflix TV-Serien Scraper machen, z.B. alle Filminformation, beste Kinofilme oder die besten Kinofilmen. Sie können alles scrapen, was Sie wollen.
Tipps!
Wenn Sie etwas Neues ausprobieren und die automatische Erkennung Sie nicht zufrieden stellt, können Sie uns gerne unter support@octoparse.com kontaktieren. Unser professioneller Support wird Ihnen weiterhelfen.
Zusammenfassung
Mit den oben beschriebenen Schritten kann jeder, auch jemand ohne Programmierkenntnisse, einen Film-Crawler mit Octoparse erstellen und mehr als 100.000 Zeilen an Filminformationen erhalten.
Abgesehen von den Daten geht es vor allem um die erlernten Fähigkeiten, die äußerst nützlich sind, wenn man Daten für die Marktforschung, die Analyse und viele andere Dinge benötigt.
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise: Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen: Octoparse für Windows und MacOs
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



