Ein Arbeitsagentur Scraper ist ein spezielles Software-Tool, das entwickelt wurde, um automatisch Daten von der Webseite der Arbeitsagentur zu sammeln. Diese Daten können für verschiedene Zwecke wie die Analyse von Arbeitsmarktdaten oder das Aggregieren von Stellenanzeigen verwendet werden. Solche Tools erleichtern die systematische Erfassung und Verarbeitung von öffentlich zugänglichen Informationen, sind jedoch rechtlich und ethisch sorgfältig zu nutzen.
Was ist ein Arbeitsagentur Scraper?
Ein Arbeitsagentur Scraper ist ein Software-Tool oder Skript, das entwickelt wurde, um Daten von den Webseiten der Arbeitsagentur (z.B. der Bundesagentur für Arbeit in Deutschland) automatisch zu sammeln oder zu “scrapen”. Diese Daten könnten Stellenanzeigen, Arbeitsmarktstatistiken, Ausbildungsplätze oder andere öffentlich zugängliche Informationen sein, die auf den Webseiten der Arbeitsagentur verfügbar sind.
Der Einsatz eines solchen Scrapers kann in verschiedenen Kontexten erfolgen, zum Beispiel:
- Jobportale: Aggregieren von Stellenanzeigen, um sie auf einer eigenen Plattform darzustellen.
- Datenanalyse: Sammeln von Daten für die Analyse von Trends auf dem Arbeitsmarkt.
- Wissenschaftliche Forschung: Erfassen von Daten für Forschungsprojekte im Bereich Arbeitsmarkt und Wirtschaft.
- Automatisierung von Bewerbungen: Automatisches Auslesen und Weiterverarbeiten von Jobangeboten, um Bewerbungsprozesse zu optimieren.
Es ist jedoch wichtig zu beachten, dass das Scrapen von Webseiten, insbesondere von staatlichen oder öffentlichen Webseiten, rechtliche Implikationen haben kann. Es sollte sichergestellt werden, dass das Scraping im Einklang mit den Nutzungsbedingungen der Webseite und den geltenden Datenschutzgesetzen steht.
Wie funktioniert ein Arbeitsagentur Scraper?
Ein Arbeitsagentur Scraper ist ein automatisiertes Werkzeug, das entwickelt wurde, um systematisch Daten von der Webseite der Arbeitsagentur zu sammeln und zu verarbeiten, wobei es die Struktur der Webseite analysiert und relevante Informationen extrahiert und speichert.
Wie kann man Arbeitsagentur.de mit Python
Ein einfacher Python-basierter Scraper könnte mit Bibliotheken wie requests (zum Abrufen von HTML-Seiten) und BeautifulSoup (zum Parsen und Extrahieren von Daten) erstellt werden. Für komplexere Aufgaben, wie das Scrapen von JavaScript-geladenen Inhalten, könnte Selenium verwendet werden, das einen Browser simuliert.
Das Scrapen von arbeitsagentur.de oder anderen ähnlichen Webseiten in Python kann mithilfe von Bibliotheken wie requests, BeautifulSoup, und für dynamische Inhalte auch mit Selenium durchgeführt werden. Hier ist ein Beispiel für den Prozess:
Schritt 1: Installieren der benötigten Bibliotheken
Zuerst müssen Sie sicherstellen, dass die erforderlichen Python-Bibliotheken installiert sind:
Schritt 2: Einfache Seite scrapen
Wenn die Webseite keine dynamischen Inhalte verwendet, können Sie direkt requests und BeautifulSoup verwenden:
Schritt 3: Dynamische Inhalte mit Selenium scrapen
Für Seiten, die Inhalte dynamisch mit JavaScript laden (z. B. bei Verwendung von AJAX), ist Selenium notwendig:
Schritt 4: Handhabung von Paginierung und dynamischem Content
Wenn die Seite über mehrere Seiten paginiert, müssen Sie möglicherweise eine Schleife implementieren, die alle Seiten durchgeht und die entsprechenden Daten abruft.
Das Scrapen von arbeitsagentur.de mit Python kann zwar nützlich sein, ist jedoch mit verschiedenen rechtlichen, technischen und ethischen Herausforderungen verbunden. Vor dem Einsatz eines Scrapers sollte man diese Nachteile sorgfältig abwägen und sicherstellen, dass der Scraper im Einklang mit den geltenden Gesetzen und Best Practices betrieben wird.
Wie kann man Arbeitsagentur effizient scrapen
Wir haben jetzt gesehen, wie wichtig Web-Scraping für Arbeitsagentur ist. In diesem Teil werden wir Ihnen zeigen, wie Sie mit Octoparse Stellenanzeigen für Arbeitsagentur scrapen können. Der Aufbau eines Job-Scrapers mit Octoparse erfordert nur vier Schritte, so dass ihr die meiste Zeit mit anderen Bereichen der Einrichtung eines Jobs verbringen könnt, z. B. mit der Erstellung des Frontends und der Entwicklung des Posting-Flows.
Wenn Sie zum ersten Mal Stellenanzeigen auslesen, laden Sie bitte Octoparse kostenlos herunter und installieren Sie es auf Ihrem Gerät. Dann kannst du dich für ein neues Konto anmelden oder dich mit deinem Google- oder Microsoft-Konto einloggen, um die leistungsstarken Funktionen von Octoparse freizuschalten.
Schritt 1: Erstellen Sie eine neue Aufgabe für das Scraping von Arbeitsagentur
Kopieren Sie die URL der Seite, von der Sie Stellenanzeigen abrufen möchten, und fügen Sie sie in die Suchleiste von Octoparse ein. Klicken Sie dann auf „Starten“, um eine neue Aufgabe zu erstellen.
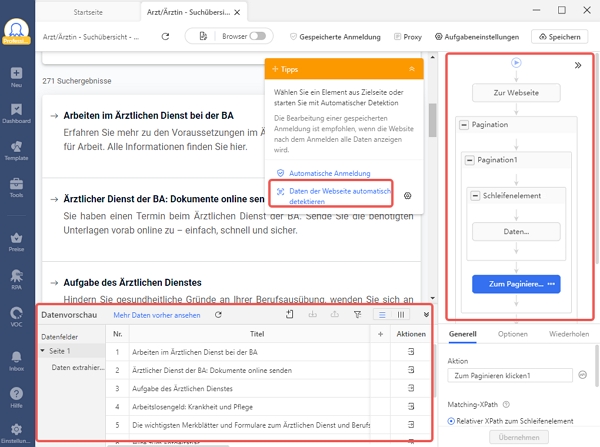
Schritt 2: Automatische Erkennung
Warten Sie, bis die Seite im integrierten Browser von Octoparse vollständig geladen ist (das kann einige Sekunden dauern), und klicken Sie dann in den Tipps auf „Webpage-Daten automatisch erkennen“. Danach wird Octoparse die gesamte Seite scannen und „erraten“, nach welchen Daten Sie suchen.
Wenn Sie z. B. versuchen, Stellenanzeigen von Indeed zu scrapen, wird Octoparse den Titel der Stelle, den Namen des Unternehmens, den Ort, die Gehaltsstufe, die Art der Stelle, den Tag der Veröffentlichung usw. auf der Seite für Sie hervorheben. Anschließend können Sie überprüfen, ob alle gewünschten Daten ausgewählt wurden. Sie können auch eine Vorschau aller erkannten Datenfelder im Bereich „Datenvorschau“ am unteren Rand anzeigen.
Schritt 3: Erstellen Sie den Workflow für Arbeitsagentur
Sobald Sie alle gewünschten Daten ausgewählt haben, klicken Sie im Bereich Tipps auf „Workflow erstellen“. Daraufhin wird auf der rechten Seite ein automatisch generierter Workflow angezeigt. Der Workflow zeigt jede Aktion des Job Scrapers. Wenn Sie ihn von oben nach unten lesen, können Sie leicht verstehen, wie Ihr Scraper funktioniert.
Sie können auch auf jede Aktion des Workflows klicken, um zu überprüfen, ob die Aktion wie erwartet funktioniert. Wenn eine Aktion nicht funktioniert, können Sie sie aus dem Workflow entfernen und neue Aktionen hinzufügen, um ihn zu ändern und die benötigten Auftragsdaten zu erhalten.
Schritt 4: Führen Sie die Aufgabe aus und exportieren Sie die ausgewerteten Daten
Nachdem Sie alle Details überprüft haben, klicken Sie auf die Schaltfläche Ausführen, um die Aufgabe zu starten. Sie können ihn direkt auf Ihrem Gerät ausführen oder ihn an die Octoparse Cloud Server übergeben. Im Vergleich zur lokalen Ausführung des Scrapers ist die Octoparse-Cloud-Plattform die perfekte Wahl für große Aufgaben, und die Cloud-Server können rund um die Uhr für Sie arbeiten. Dann können Sie aktuelle Stellenanzeigen für Ihre Job-Aggregatoren erhalten.
Wenn der Lauf abgeschlossen ist, exportieren Sie die gescrapten Stellenausschreibungen in eine lokale Datei wie Excel, CSV, JSON usw. oder in eine Datenbank wie Google Sheets zur weiteren Verwendung.
Arbeitsagentur Scraper
Mit Octoparse stehen Ihnen über 100 benutzerfreundliche Vorlagen zur Verfügung, um Daten schnell und einfach zu extrahieren. Darüber hinaus ermöglicht Ihnen die Octoparse-Vorlage die gezielte Extraktion der gewünschten Daten auf einfache Weise. Die Benutzerfreundlichkeit der Octoparse-Vorlage ist besonders hervorzuheben!
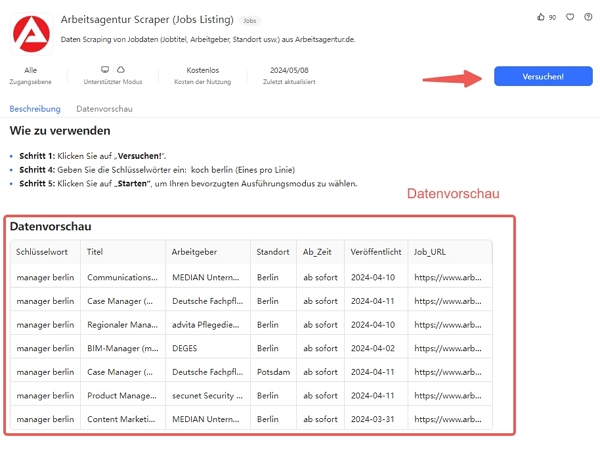
https://www.octoparse.de/template/arbeitsagentur-scraper-jobs-listing
Zusammenfassung
Web Scraping ist essenziell für die Arbeitsagentur. Codierungsfreie Lösungen erleichtern das Sammeln umfangreicher Informationen, sodass Sie sich auf die wichtigsten Daten konzentrieren können. Testen Sie es 14 Tage lang kostenlos.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬




