reCAPTCHA ist eine der am häufigsten von Websites verwendeten Sicherheitsmaßnahmen, um zu verhindern, dass automatisierte Bots auf ihre Inhalte zugreifen. Das von Google entwickelte Tool soll zwischen menschlichen Benutzern und automatisierten Skripten unterscheiden und stellt somit eine erhebliche Herausforderung für Web Scraper und Automatisierungstools dar.
Für Unternehmen und Forscher, die sich bei der Datenerfassung auf Web Scraping verlassen, kann die Begegnung mit reCAPTCHA ein frustrierendes Hindernis sein. Obwohl sein Hauptzweck darin besteht, bösartige Bots zu verhindern, kann sogar die ethische Datenextraktion gestört werden. In diesem Leitfaden untersuchen wir 4 verschiedene Arten von reCAPTCHA, die rechtlichen Auswirkungen und bieten praktische Methoden zum Umgehen von reCAPTCHA effektiv und verantwortungsbewusst beim Web Scraping.
4 verschiedene Arten von reCAPTCHA
Bevor wir besprechen, wie man reCAPTCHA umgeht, ist es wichtig, die verschiedenen Versionen und ihre Funktionsweise zu verstehen.
1. reCAPTCHA v2 (Kontrollkästchen „Ich bin kein Roboter“)
Dies ist das am häufigsten vorkommende CAPTCHA. Benutzer müssen ein Kontrollkästchen mit der Aufschrift „Ich bin kein Roboter“ anklicken. Wenn Google Bot-Aktivitäten vermutet, wird ein zusätzlicher bildbasierter CAPTCHA-Test angezeigt.
Und so geht’s:
- Es verfolgt das Benutzerverhalten (Mausbewegungen, Klicks, Sitzungsverlauf).
- Bei Verdacht treten Herausforderungen auf, beispielsweise die Auswahl von Objekten in Bildern.
2. reCAPTCHA v2 Unsichtbar
Anders als bei der Kontrollkästchenversion ist bei Invisible reCAPTCHA v2 keine Benutzerinteraktion erforderlich, sofern keine verdächtige Aktivität erkannt wird.
Und so geht’s:
- Google analysiert die Benutzerinteraktionen auf der Website.
- Wenn es Bot-Verhalten erkennt, löst es ein bildbasiertes CAPTCHA aus.
3. reCAPTCHA v3 (Score-basiertes CAPTCHA)
Diese Version unterbricht Benutzer nicht mit Herausforderungen, sondern weist stattdessen eine Punktzahl (0,0 – 1,0) zu , basierend darauf, wie wahrscheinlich es ist, dass eine Anfrage von einem Bot stammt.
Und so geht’s:
- Websites legen einen Punkteschwellenwert fest; Benutzer mit niedriger Punktzahl können blockiert werden.
- Google wertet das Nutzerverhalten, den Geräte-Fingerprinting und den Browserverlauf aus.
4. reCAPTCHA Unternehmen
Dies ist eine erweiterte Version, hauptsächlich für Hochsicherheitsanwendungen wie Bankgeschäfte oder vertrauliche Konten.
Und so geht’s:
- Es nutzt eine KI-gestützte Risikoanalyse, um die Bot-Aktivität zu ermitteln.
- Websites erhalten individuelle Sicherheitseinstellungen basierend auf ihren Anforderungen.
Jeder dieser Typen stellt Web Scraper vor unterschiedliche Herausforderungen. Es gibt jedoch Möglichkeiten, reCAPTCHA effektiv und legal zu umgehen.
Ist es legal, reCAPTCHA zu überspringen?
Das Umgehen von reCAPTCHA ist rechtlich und ethisch eine Grauzone . Zwar ist es nicht direkt illegal, aber ein Verstoß gegen die Nutzungsbedingungen einer Website kann zu Einschränkungen, Sperren oder sogar rechtlichen Schritten führen. Folgendes müssen Sie beachten:
Situationen, in denen es akzeptabel ist
- Scraping öffentlich verfügbarer Daten, die nicht hinter einem Login stehen.
- Verwenden Sie anstelle von Scraping eine API, wenn die Website eine bereitstellt.
- Für akademische, Forschungs- oder Compliance-Zwecke, bei denen eine Datenerfassung erforderlich ist.
Situationen, in denen es riskant sein kann
- Umgehen von reCAPTCHA, um auf private Daten zuzugreifen oder sich bei Konten anzumelden, die Ihnen nicht gehören.
- Verwenden von Scraping für Spam, Betrug oder böswillige Zwecke (dies kann rechtliche Konsequenzen haben).
- Verstoß gegen die Nutzungsbedingungen einer Website (Websites können Sperren oder IP-Blockierungen aussprechen).
Das Beste ist
- Überprüfen Sie die robots.txt-Datei der Website, um zu sehen, ob Scraping zulässig ist.
- Beachten Sie die Scraping-Grenzen , indem Sie den Server nicht überlasten.
- Verwenden Sie ethische Scraping-Tools , die verantwortungsvollen Praktiken zur Datenextraktion folgen.
2 Methoden zum Umgehen von reCAPTCHA
Methode 1: Verwenden von Octoparse für Web Scraping (keine Codierung)
Octoparse ist ein benutzerfreundliches Web-Scraping-Tool. Es kann Ihnen helfen, Website-Daten automatisch und ohne Programmierung zu scrapen. Octoparse bietet die Cloud-basierte Scraping-Funktion , mit der Sie CAPTCHA, einschließlich reCAPTCHA v2 , mit minimalem Aufwand umgehen können. Da es Scraping-Aufgaben in der Cloud ausführt, vermeidet es viele CAPTCHA-Trigger, die beim Scraping von lokalen Geräten auftreten.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
So lösen Sie reCAPTCHA in Octoparse manuell
Octoparse bietet eine integrierte Funktion zum Lösen von CAPTCHAs , die einfache CAPTCHAs während der Datenextraktion problemlos verarbeiten kann. Befolgen Sie die unten aufgeführten einfachen Schritte oder fahren Sie mit dem Tutorial fort, um weitere Einzelheiten zum Lösen von CAPTCHAs zu erfahren .
Schritt 1: Einen Scraping-Workflow erstellen
Verwenden Sie die automatische Erkennungsfunktion von Octoparse, um einen Scraping-Workflow zu erstellen, nachdem Sie Octoparse auf Ihrem Gerät installiert haben. Kopieren Sie einfach die URL der Zielwebsite, fügen Sie sie in das Octoparse-Bedienfeld ein und klicken Sie auf „Start“.
Schritt 2: CAPTCHA-Umgehung einrichten
Nachdem Sie den Workflow erstellt haben, klicken Sie im Workflow auf die Schaltfläche „Schritt hinzufügen“ und wählen Sie die Option „CAPTCHA lösen“ .
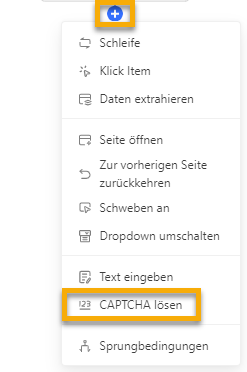
Wählen Sie als CAPTCHA-Typ „reCAPTCHA“ aus und klicken Sie auf „Übernehmen“ , um die Einstellungen zu speichern.
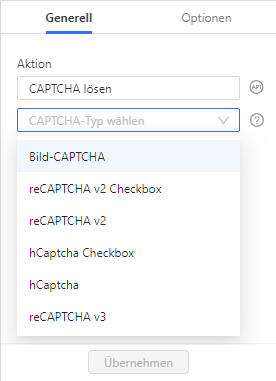
Wenn das CAPTCHA, auf das Sie stoßen, eine Schaltfläche zum Senden enthält, können Sie das Kontrollkästchen reCaptcha V2 auswählen und auf eine Schaltfläche zum Senden klicken, die Sie zur Zielseite weiterleitet.
Wählen Sie anschließend „Element anklicken/Schaltfläche anklicken“, um fortzufahren.
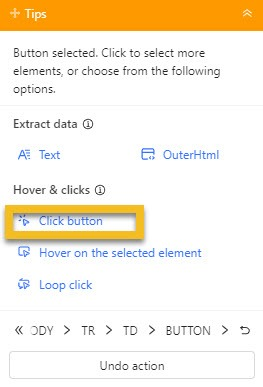
ReCaptcha wird erst bei einem tatsächlichen Datenlauf automatisch aufgelöst. Daher müssen Sie den Browse-Modus aktivieren und es manuell auflösen, um beim Erstellen der Aufgabe fortzufahren.
Schritt 3. Daten ohne Limit extrahieren
Überprüfen Sie abschließend alle Einstellungen für die Datenextraktion. Klicken Sie auf die Schaltfläche „Ausführen“ , um mit dem Datenscraping zu beginnen. Sie können die Daten als Excel-Datei oder in anderen gewünschten Formaten herunterladen.
Methode 2: Verwenden von Browserautomatisierung und KI-basierten Lösungen
Eine weitere effektive Methode ist die Verwendung von Browser-Automatisierungstools wie Selenium, Puppeteer oder Playwright . Diese Tools können menschliches Verhalten nachahmen, um die Wahrscheinlichkeit zu verringern, dass reCAPTCHA ausgelöst wird.
So funktioniert es:
- Selenium & Puppeteer : Automatisieren Sie Interaktionen wie Scrollen, Klicken und Texteingabe.
- KI-basierte CAPTCHA-Löser : Verwenden Sie maschinelles Lernen, um CAPTCHA-Muster zu erkennen.
- Headless-Browser : Simulieren echte Browser, aber das Erkennungsrisiko kann steigen.
Schritte zur Reduzierung der CAPTCHA-Erkennung durch Browser-Automatisierung
- Verwenden Sie „undetected_chromedriver“ : Ein modifizierter Chrome-Treiber, der eine einfache Bot-Erkennung verhindert.
- Fügen Sie zufällige Verzögerungen und Mausbewegungen hinzu : Imitieren Sie das Surfen wie ein Mensch.
- Verwenden Sie echte Benutzeragenten: Stellen Sie sicher, dass der Scraper wie ein echter Browser aussieht.
Diese Methoden können zwar funktionieren, erfordern jedoch technisches Wissen und sind möglicherweise nicht so zuverlässig wie Cloud-basierte Lösungen wie Octoparse.
6 Tipps zur Reduzierung der reCAPTCHA-Häufigkeit beim Scraping
Anstatt reCAPTCHA zu umgehen, ist es sinnvoller, es nicht auszulösen . Hier sind einige Tipps, um die Häufigkeit zu reduzieren.
1. Verlangsamen Sie Ihre Anfragen : Wenn Sie in kurzer Zeit zu viele Anfragen senden, ist das ein Warnsignal. Fügen Sie zwischen den Anfragen zufällige Verzögerungen ein, um menschliches Verhalten nachzuahmen.
2. Verwenden Sie Proxys und wechseln Sie die IP-Adressen : Verwenden Sie private oder mobile Proxys anstelle von Rechenzentrums-Proxys. Wechseln Sie die Proxys, um eine Erkennung zu vermeiden und IP-Sperren zu verhindern.
3. Menschliches Verhalten nachahmen: Bots bewegen sich vorhersehbar, echte Benutzer nicht. Randomisieren Sie Scrollen, Mausbewegungen und Klicks mit Selenium. Variieren Sie Navigationspfade und verwenden Sie unterschiedliche Referrer, um organisch zu wirken.
4. Rotieren Sie User-Agents und Header: Verwenden Sie echte Browser-Header und rotieren Sie User-Agents, um eine Bot-Erkennung zu vermeiden.
5. Sitzungen aufrechterhalten: Vermeiden Sie das Starten einer neuen Sitzung bei jeder Anforderung ; verwenden Sie dauerhafte Cookies.
6. Scrapen außerhalb der Stoßzeiten: Scraping in der Nacht oder am frühen Morgen verringert das Risiko einer Entdeckung, da der Website-Verkehr geringer ist.
Hier sind weitere Tipps für Sie, um beim Web Scraping reibungsloser zu werden. Lesen Sie den Artikel: 9 Tipps zum Web Crawling, ohne blockiert zu werden
Zusammenfassung
Das Umgehen von reCAPTCHA ist für Web Scraper eine Herausforderung, doch die Verwendung der richtigen Tools und Techniken kann dazu beitragen, die Erkennung zu verringern und das Lösen von CAPTCHAs zu automatisieren .
- Für nicht-technische Benutzer bietet Octoparse eine integrierte CAPTCHA-Lösungsfunktion und unterstützt CAPTCHA-Lösungsdienste von Drittanbietern.
- Für Entwickler können Browser- Automatisierungstools wie Selenium und KI-basierte Lösungen verwendet werden.
Obwohl das Umgehen von CAPTCHA möglich ist, sollten beim Scraping immer ethische Praktiken befolgt werden, um Verstöße gegen die Nutzungsbedingungen einer Website zu vermeiden. Durch die Implementierung dieser Strategien können Sie effizientes und verantwortungsvolles Web Scraping sicherstellen und gleichzeitig CAPTCHA-bedingte Störungen minimieren.
Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



