Immer öfter ist es notwendig, Daten aus Webseiten auszulesen. Datenbezogene Projekte im Bereich Unternehmensanalyse, Preisüberwachung oder Nachrichtenaggregator erhöhen den Bedarf an Daten aus den Internetseiten. Mit dem herkömmlichen Daten manuell zu kopieren und in eine Datei einzufügen, wird zu viel Zeit verschwendet. Hilfreiche Online-Tools wie zum Beispiel der Python Web Scraper machen das Web Scraping einfach und enorm schnell. Im folgenden Beitrag zeigen wir Ihnen, wie einfach das Web Scraping mit Python funktioniert. Sie werden sehen, dass Sie innerhalb kurzer Zeit ein Profi im Daten extrahieren werden.
Weshalb Python für das Scraping?
Python ist eine sehr beliebte Programmiersprache und wird sehr gerne von Entwicklern verwendet. Aus diesem Grund eignet sie sich hervorragend für das Erstellen einer Web-Scraping-Software. Webseiten werden jedoch laufend neu angepasst. Die Webinhalte werden verändert oder an die neuesten Technologien angepasst. Zu den Veränderungen zählt selbstverständlich auch das Design. Anpassungen und neue Seitenbestandteile sind darum keine Seltenheit. Ein Web Scraper wird genau für diese spezifischen Strukturen von Webseiten geschrieben. Verändert sich diese Seitenstruktur muss der Scraper danach angepasst werden. Mit Python Web Scraping ist die Anpassung sehr einfach und rasch durchgeführt. So können Sie rasch und unkompliziert auf jede Veränderung rasch reagieren.
Der Python Web Scraper besitzt eine enorme Stärke im Bereich Abruf von Web Ressourcen und Textverarbeitung. Diese Basis macht ihn zu einer technischen Grundlage für das Web Scraping. Python bietet auch einen Standard für die Verarbeitung und Analyse von Daten. Er eignet sich dadurch generell als wertvolles Hilfsmittel, das durch ein reiches Programmier-Ökosystem besticht. Zu diesem Ökosystem zählen zum Beispiel
- die Bibliotheken,
- die Dokumentation,
- die Sprachreferenz,
- Open-Source-Projekte
- Forenbeiträge
- Blogartikel
- Burgreports
Ferner bestehen mehrere spezielle Bibliotheken für das Web Scraping mit Python. Die bekanntesten Bibliotheken sind:
- BeautifulSoup
- Scrapy
- Selenium
Einführung in den Python Web Scraper
Das Web Scraping stellt eine hilfreiche Technik dar, die unstrukturierte Daten, zum Beispiel HTML, in strukturierte Daten umwandeln kann. Neben der Nutzung von Python für die Code-Erstellung ist es möglich, Informationen von Webseiten mithilfe von APIs oder Datenextraktionstools wie Octoparse zu erhalten.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
Mehrere große Webseiten, zum Beispiel Twitter oder Airbnb, bieten den Entwicklern APIs zur Verfügung, um auf die Daten zuzugreifen. API bedeutet “Application Programming Interface” oder auf Deutsch Anwendungsprogrammierschnittstelle. Damit wird es möglich, dass zwei Anwendungen miteinander in Kontakt treten können. APIs sind für viele Menschen ein guter Weg, um Daten von Webseiten zu bekommen.
API-Dienste werden jedoch nur von sehr wenigen Webseiten angeboten. Es kommt auch vor, dass die angebotenen APIs nicht die erforderlichen Daten liefern. Eine Lösung, die äußerst flexibel und leistungsstark ist, ist das Schreiben von Python-Skripten, um einen Web Crawler zu erstellen. Hier hilft zum Beispiel Selenium, das im Python Web Scraper enthalten ist.
Warum wird Python und keine andere Sprache eingesetzt?
✅ Sehr flexibel: Webseiten werden rasch aktualisiert, wobei das nicht nur den Inhalt, sondern auch die Webstruktur betrifft. Mit Python hat man eine einfache Sprache zur Hand, die sehr produktiv und berechenbar ist. Nutzer können einen Code einfach verändern und dadurch mit den Geschwindigkeiten der Webseiten-Updates mithalten.
✅ Sehr leistungsstark: Mit Python erhält man eine enorme Bibliotheken-Sammlung. So ist es zum Beispiel möglich, mit der Hilfe von BeautifulSoup4 und Requests URLs anzurufen. Damit können Sie Informationen aus Webseiten extrahieren. Müssen Anti-Scraping-Techniken umgangen werden, kann Selenium sehr hilfreich sein. Selenium macht es dem Web Crawler möglich, menschliches Verhalten beim Internetsurfen nachzuahmen. Bei der Verarbeitung und auch Bereinigung von Daten sind numpy, re und pandas eine hilfreiche Unterstützung.
Bibliotheken im Python Web Scraper
Der Python Web Scraper ist mit mehreren Bibliotheken ausgestattet. Damit wird das Scraping sehr einfach. Die wichtigsten Bibliotheken im Überblick:
- Bei BeautifulSoup handelt es sich um eine sehr beliebte Web Scraping Bibliothek. Sie ist benutzerfreundlich aufgebaut und die Methoden für das Navigieren, Ändern und Suchen des Parse-Baums sehr einfach. Durch BeautifulSoup wird auch die Kodierung der ein- und ausgehenden Daten übernommen.
Scrapy
- Scrapy zählt ebenfalls zu den beliebten Frameworks zur Datenextraktion. Es ist besonders gut für das Datenauslesen von APIs geeignet. Mit einigen integrierten Funktionen wie zum Beispiel das Versenden von E-Mails wird es zusätzlich sehr interessant.
Selenium
- Bei Selenium handelt es sich um keine reine Web Scraping Bibliothek. Es ist vielmehr ein umfassendes Paket für die Browser-Automatisierung. Mit diesem Tool kann die Funktionalität beim Web Scraping erweitert werden. Das Datenauslesen auf Webseiten erfolgt damit automatisiert.
Schritt für Schritt Anleitung für das Python Web Scraping
Mit der folgenden Anleitung können Sie den Python Web Scraper einfach und sicher anwenden.
Schritt 1: Die Python Bibliothek importieren
Mit dieser Anleitung zeigen wir Ihnen, wie Sie zum Beispiel Leads von Gelben Seiten abfragen können. In diesem Beispiel werden dafür zwei Bibliotheken eingesetzt. Requests in Urlaub und BeautifulSoup in bs4. Mit den beiden Bibliotheken wird der Web Crawler mit Python sehr oft aufgebaut. Zum Anfang müssen diese beiden Bibliotheken in Python Import werden. Durch das Importieren kann man die Funktionen der beiden Bibliotheken verwenden.
Schritt 2: Den HTML-Code der gewünschten Webseite extrahieren
In unserem Beispiel werden Leads von Gelben Seiten benötigt. Darum ist der HTML-Code auszulesen. Diese URL wird in der Variablen mit dem Namen URL gespeichert. Danach kann man auf den Inhalt zugreifen. Erst jetzt ist es möglich den HTML-Code im Bereich “ourUrl” speichern, indem man in request die Funktion urlopen() verwendet. Nach diesem Vorgang wird BeautifulSoup eingesetzt, um die Website zu analysieren.
Mit BeautifulSoup erhält man das Roh-HTML der Webseite. Mit der Funktion “prettify()” kann man die Daten bereinigen. Nach dem Bereinigen können diese Daten ausgedruckt werden. Durch das Ausdrucken wird ersichtlich, wie verschachtelt die Struktur der HTML ist.
Schritt 3: Die Bewertungen finden und scrapen
Im Schritt drei werden die gewünschten Daten gesucht. Wurden die Daten gefunden, können sie extrahiert werden. Auf einer Webseite hat jedes Element eine eigene HTML-ID. Damit sie überprüft werden kann, muss sie auf der Webseite detektiert werden.
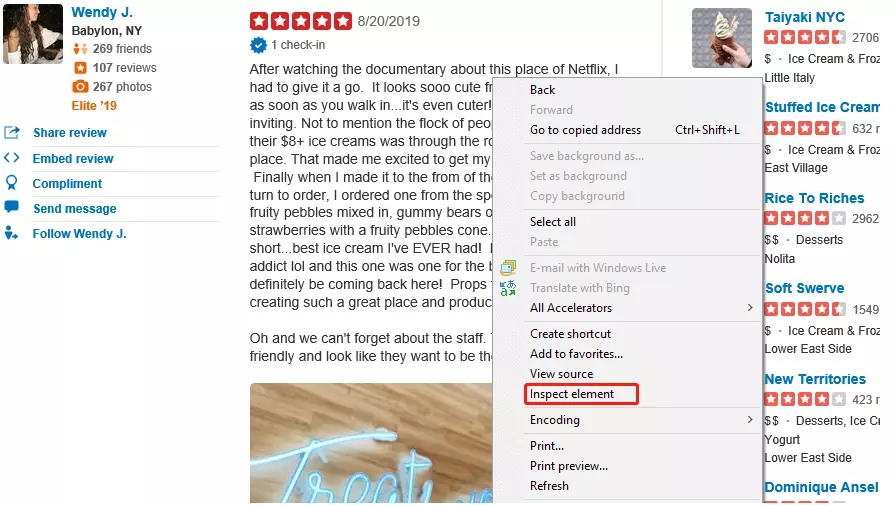
Mit der Funktion ”Inspect Element” oder je nach Browser”Inspect” kann man den HTML-Code der Bewertungen sehen. Bei diesem Beispiel befinden sich die Bewertungen unter einem Tag mit der Bezeichnung “p”. Sie müssen danach die Funktion “find_all” nutzen. Damit können Sie den übergeordneten Knotenpunkt der Bewertung herausfinden.

Dadurch ist es möglich, in einer Schleife die Tag “p” -Elemente unter diesem Knoten herausfinden. Haben Sie alle Elemente von “p” gefunden, werden diese in der leeren Liste mit dem Namen “review” gespeichert. Sie erhalten nun alle auf dieser Seite befindlichen Bewertungen.
Schritt 4: Die Bewertungen reinigen
Es ist Ihnen sicherlich aufgefallen, dass selbst nach der Bereinigung überflüssige Texte mit dem Begriff “p lang=’en’>” zu Beginn der Bewertung vorhanden sind.
Einige Bewertungen haben in der Mitte “<br/>” und am Ende “</p>”. Das “<br/>” steht in diesem Fall für den Zeilenumbruch und das “</p>” für Anfang und Ende eines HTML-Satzes. Auch die Bezeichnung “<p lang=’en’>” ist nicht benötigt, weswegen diese gelöscht werden. Wurde das Löschen vorgenommen, bleiben saubere Bewertungen übrig. In diesem Beispiel Bewertungen mit weniger als 20 Codezeilen.
Hinweis: Diese Anleitung ist gleichzusetzen mit einer Demo und ein Beispiel, wie man bei Yelp 20 Bewertungen abrufen kann! In anderen Anfragen haben Sie möglicherweise andere Situationen vor sich, die bewältigt werden müssen. Zum Beispiel sind hin und wieder Schritte wie das Umblättern oder zu anderen Seiten gehen notwendig. Ohne diese Schritte ist es oft nicht möglich, die Bewertungen anderer Webseiten auszulesen. Möchten Sie andere Informationen scrapen wie zum Beispiel den Ort des Rezensenten oder seinen Namen, sind weitere Schritte notwendig, um die gewünschten Informationen zu erhalten. Um weitere Informationen zu erhalten, ist es notwendig, weitere Bibliotheken und Funktionen einzusetzen. Ein Beispiel ist die Nutzung von Selenium oder das Erlernen der regulären Ausdrücke.
FAQs
1. Eignet sich Python für das Web Scraping?
Web Scraping mit Python eignet sich hervorragend durch das breite Angebot an Bibliotheken. Zum Beispiel BeautifulSoup oder Scrapy. Diese Bibliotheken erweitern die Funktionen des Python Web Scraper enorm.
2. Welche Sprache wird beim Web Scraping am häufigsten genutzt?
Python ist durch die hohe Benutzerfreundlichkeit, leichte Lesbarkeit und die umfangreichen Bibliotheken eine äußerst beliebte Sprache. Der Python Web Scraper ist sehr umfangreich, komplex und flexibel. Bei vielen Entwicklern ist er deswegen die erste Wahl.
3. Ist Python wirklich noch aktuell?
Derzeit ist der Python Web Scraper das am häufigsten genutztes Tool. Der Grund ist, dass sich die Skriptsprachen auf Webanwendungen konzentrieren. Python besteht seit dem Jahr 1991. Python und damit der Python Web Scraper finden Einsatz in mehreren Bereichen wie zum Beispiel Grafik, künstliche Intelligenz und weiteren Bereichen.
Fazit – Web Scraping mit Octoparse
Suchen Sie eine einfache Möglichkeit für das Web Scraping? Octoparse ist eine gute Wahl für einfaches und rasches Web Scraping mit Python. Mit Octoparse haben Sie einen leistungsstarken Partner, der Ihnen hilft Informationen aus dem Internet zu erhalten.
Interaktionen, die automatisch durchgeführt werden, zum Beispiel und das Extrahieren von benötigten Daten in verschiedenen Formaten. Die Einfachheit des Python Web Scraping von Octoparse ist überzeugend und auch für Anfänger geeignet. Die Bibliotheken sind einfach zu nutzen und erleichtern das Daten-Scraping enorm. Haben Sie einmal das Web Scraping mit Python getestet, dann werden Sie sicherlich überzeugt sein.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



