Craigslist ist die größte Website für Kleinanzeigen in den USA und eines der beliebtesten Portale für die Anzeige lokaler Dienstleistungen und Produkten. Craigslist ist nicht nur in den USA bekannt, sondern deckt auch 70 Länder ab und verzeichnet mehr als 20 Milliarden Seitenaufrufe pro Monat.
Auf Craigslist sind die Informationen leicht zu lesen, aber schwer herunterzuladen. Es kann extrem schwierig sein, die spezifischen Informationen zu sammeln. Da die von Craigslist verwendete API jedoch nur das Einstellen von Anzeigen erlaubt, können Sie keine reinen Lesedaten abrufen.
Wenn Sie Daten von Craigslist auslesen möchten und nicht wissen, wie das geht, ist dies der richtige Artikel für Sie. In diesem Artikel werden wir darüber sprechen, warum man Craigslist scrapen sollte, ob es irgendwelche Regeln gibt und wie man es Schritt für Schritt mit Octoparse macht.
Warum extrahiert man die Daten aus Craigslist?
Craigslist sammelt eine große Menge von Informationen. Zweifellos ist es eine der beliebsten Website zu scrapen. Hier sind einige typischen Gründe dafür.
1> Jeder kann aus erster Hand die Informationen über Häuser, Autos, Computer und vieles mehr erhalten.
2> Ähnlich wie Yellowpages und Yelp kann Craigslist für Entwicklung der potentiellen Kunden zu benutzen.
3> Auf Craigslist kann man auch die benutzten Dingen wiederverkaufen. Mit gut strukturierten Daten kann man die Preise besser analysieren und einen neuen Preis für den Weiterverkauf festlegen.
4> Craigslist ist voll von wertvollen Informationen der Branchen und Geschäften. Wenn Sie Geschäftsführer*in sind, ist es eine gute Plattform für die Überwachung und Analysierung Ihrer Konkurrenten. Damit können Sie in Echtzeit deren Strategien informiert sind und sich einen Wettbewerbsvorteil verschaffen.
Ist Extraktion von Craigslist illegal?
Craigslist ist eine der beliebtesten auch schwierigsten Websites zum Scrapen. Der Grund dafür ist einfach: Trotz der Craigslist-API ist es nicht erlaubt, die Daten abzurufen. Die Nutzern dürfen nur die Informationen und Anzeigen posten.
Genau wie bei Facebook und LinkedIn ist in den Nutzungsbedingungen von Craigslist eindeutig festgelegt, dass alle Arten von Robots, Spiders, Scripts, Scrapers und Crawlers verboten sind.
Craigslist hat verschiedene Technologien und rechtliche Praktiken gegen Datenextraktion eingesetzt. Es ist illegal, wenn Sie vertrauliche Informationen zu Gewinnzwecken auslesen, aber wenn Sie öffentliche Daten nur für den persönlichen Gebrauch auslesen, sollte es OK sein.
Wie kann man die Daten von Craigslist extrahieren?
Wenn Sie mit Programmierung sehr vertraut sind, können Sie ein Scraping-Programm mit Pythonkenntnissen nach dem Hinweis des Tutorials Python tutorial on scraping East Bay Area Craigslist for apartments enwickeln.
Aber es ist sehr kompliziert für diese, die keine Ahnung für die Progammierung haben. Wenn Sie auch zu diesen gehören, d.h. keine Erfahrungen beim Programmieren haben aber ein einfaches und schnelles Scraping-Tool brauchen, dann ist Octoparse eine beste Wahl!
Mit dem lesitungsfähigen Scraping-Tool kann man ohne Progammierungskenntnisse die Datenextraktion von einer Website sehr einfach und effizient verwirklichen. Octoparse hilft Ihnen bei dem Scraping aller gewünschten Daten aus Craigslist mit nur einigen einfachen Klicken problemlos extrahieren und die Ergebnisse in Excel, CSV; HTML und Datenbanken exportieren.
Hier ist ein Bespiel für die Datenausgabe, die mit Octoparse aus Craigslist extrahiert werden.
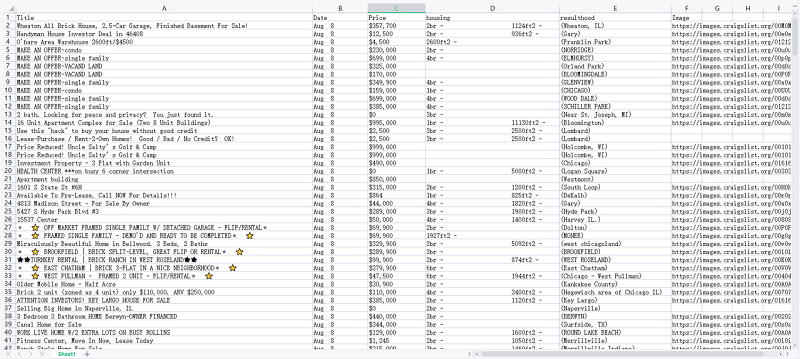
Extraktion von Craigslist mit Octoparse
Im vorliegenden Teil ist Ihnen Octoparse als Scraping-Tool voegestellt. Dann wird ein praktisches Beispiel angezeigt. Genauer gesagt wird die Daten sowie die Infos von Wohnungen/Immobilien in Chicago aus dieser URL https://chicago.craigslist.org/d/housing-real-estate/search/rea?lang=en&cc=gb gescrapt.
Wenn Sie das mit uns zusammen machen möchten, ist zuerst die Installation von Octoparse auf Ihrem Computer benötigt.
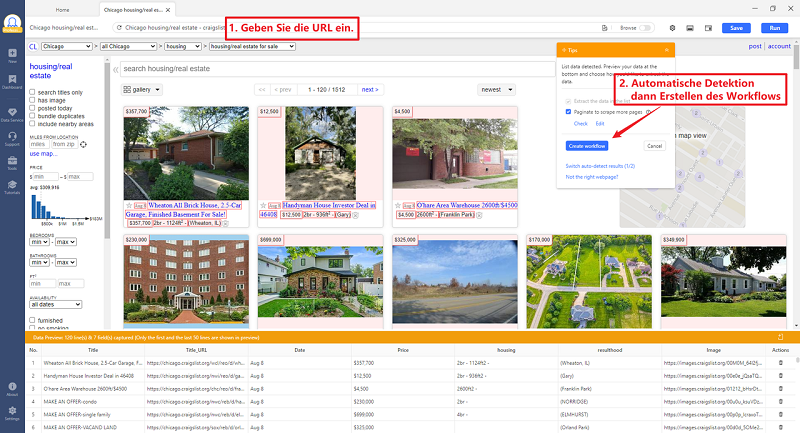
Schritt 1: Geben Sie erstens die Ziel-URL von Craigslist ein, um einen Crawler zu erstellen.
Nach dem Eingeben der URL in Octoparse, beginnt es automatisch alle Datenfeldern auf der Website zu erkennen. Wie Sie sehen, sind die zu extrahierenden Daten in rot auch im Vorschaufenster vorgestellt.
Schritt 2: Speichern Sie die Extraktionseinstellungen
Nachdem Sie es bestimmt haben, dass die Datenfelder Ihren Anforderungen entsprechen, klicken Sie auf “Save settings” , und Octoparse wird schließlich einen Workflow automatisch auf der rechten Seite generieren.
Schritt 3: Starten Sie den Scraping-Workflow, um Daten auszulesen.
Abschließend müssen Sie nur noch den Crawler speichern und auf “Run” klicken, um die Extraktion zu starten. Der Scraping-Prozess kann innerhalb von 5 Minuten fertiggestellt werden.
Mehrwert durch Tipps und Best Practices
- Vermeiden Sie Blockierungen durch Craigslist: Biete Strategien an, um sicherzustellen, dass Octoparse keine IP-Sperren oder CAPTCHA-Abfragen verursacht, z.B. durch Nutzung von Proxys.
- Effizienten Sie Datenverarbeitung: Tipps zur effizienten Verarbeitung und Strukturierung der extrahierten Daten, damit der Leser die Daten später besser nutzen kann.
Zusammenfassung
Data Scraping Tool kann nicht nur alle Daten von Craigslist auslesen, sondern auch in vielen anderen Bereichen eingesetzt werden, z. B. im Marketing, im E-Commerce und im Einzelhandel, in der Datenwissenschaft, in der Aktien- und Finanzforschung, im Datenjournalismus, in der Wissenschaft, im Risikomanagement, in der Versicherungsbranche und in vielen anderen Bereichen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



