Bild.de ist die Online-Präsenz der deutschen Boulevardzeitung „Bild“, die zu den auflagenstärksten Zeitungen in Deutschland gehört. Die Webseite bietet Nachrichten aus verschiedenen Bereichen, darunter Politik, Sport, Unterhaltung und Lifestyle. Bild.de ist bekannt für seine reißerische Berichterstattung und zahlreiche Videos sowie Fotostrecken. Die Plattform zieht ein breites Publikum an und ist oft auch in sozialen Medien aktiv, um ihre Inhalte zu verbreiten.
Web Scraping von Bild.de wird häufig genutzt, um umfangreiche Informationen wie Bilder, Artikel und Autorenprofile für Inhaltsanalysen und Forschungszwecke zu sammeln. Dies liefert wertvolle Erkenntnisse über das Engagement der Autoren, die Beliebtheit von Themen und Inhaltstrends, die für akademische Studien, Marktforschung, Journalismus und KI-Training von Bedeutung sind. Schauen wir uns nun die Hauptgründe an, warum Nutzer Bild.de scrapen möchten.
Die wichtigsten Gründe für Scraping Bild.de
Nachrichtenaggregation: Nachrichtenaggregation von bild.de ermöglicht es, die neuesten und relevantesten Nachrichten aus verschiedenen Themenbereichen zu sammeln. Dies hilft dabei, ein umfassendes Bild der aktuellen Ereignisse zu erhalten und Trends frühzeitig zu erkennen. Zudem können aggregierte Daten genutzt werden, um Inhalte für eigene Plattformen zu erstellen oder um die Berichterstattung über wichtige Themen zu optimieren.
Marktanalyse: Bei der Marktanalyse von bild.de kann man das Leserengagement, die häufigsten Themen und die Art der Berichterstattung untersuchen. Durch das Scraping von Artikeln, Kommentaren und Interaktionen lässt sich erkennen, welche Inhalte bei der Zielgruppe besonders gut ankommen.
Inhaltsforschung: Für akademische oder journalistische Studien zur Medienberichterstattung. Bei der Marktanalyse von bild.de kann man das Leserengagement, die häufigsten Themen und die Art der Berichterstattung untersuchen. Durch das Scraping von Artikeln, Kommentaren und Interaktionen lässt sich erkennen, welche Inhalte bei der Zielgruppe besonders gut ankommen. Diese Daten können helfen, gezielte Marketingstrategien zu entwickeln und die eigenen Angebote an die Interessen der Verbraucher anzupassen.
SEO-Insights: Um Schlüsselwörter und Themen zu identifizieren, die Traffic generieren.
Wettbewerbsbeobachtung:Die Wettbewerbsbeobachtung durch das Scraping von bild.de ermöglicht es, die Inhalte, Strategien und Engagement-Methoden von Mitbewerbern zu analysieren. Um zu verfolgen, was Wettbewerber veröffentlichen und wie sie ihre Zielgruppe ansprechen.
Data Mining für maschinelles Lernen: Bild.dekann eine wertvolle Quelle für Textdaten für Menschen in den Bereichen Künstliche Intelligenz (KI) und Datenwissenschaft sein. Sie können die vielfältigen Inhalte von Bild.de für maschinelles Lernen, KI-Modelltraining und NLP-Anwendungen (Natural Language Processing) nutzen, indem Sie sie auslesen.
Web Scraping Methoden für Scraping Bild.de
Um bild.de zu sammeln, kann man verschiedene Methoden verwenden, wie z.B. Python, oder Sammelsoftware, Details dazu finden Sie in diesem Artikel.
Scraping von Bild.de Bilder mit Python
Web-Scraping-Tools wie BeautifulSoup und Scrapy haben sich in der Tat zu einer festen Größe im Bereich der Datenerfassung und -verwaltung entwickelt. BeautifulSoup, ein benutzerfreundliches Python-Paket, vereinfacht den Prozess des Parsens von HTML- und XML-Dokumenten für das Scraping von Bild,de auf wunderbare Weise. Auf der anderen Seite bietet Scrapy eine robuste und flexible Lösung für größere und komplexere Scraping-Aufgaben in Bild.de, wie z. B. verschiedene Artikel. Mit seiner Fähigkeit, leistungsstarke Spider-Bots zu erstellen, erweist sich Scrapy als ideales Werkzeug für die fortgeschrittene Datenextraktion aus Bild.de.
So müssen Python-Benutzer, die Online-Material von Bild.de scrapen wollen, Anfragen und Web-Scraping-Pakete wie Beautiful Soup verwenden. Diese Bibliotheken ermöglichen es, HTML-Inhalte von Websites zu extrahieren, um sie für die Datenanalyse zu verwenden. Hier finden Sie eine kurze Erklärung, wie Sie diese Aufgabe erledigen können:
Bitte beachten Sie, dass Sie die Nutzungsbedingungen und die robots.txt-Datei auf jeder Website lesen und einhalten sollten, bevor Sie versuchen, sie zu scrapen. Die Nutzungsbedingungen von Bild.de können durch Web Scraping verletzt werden, was zur Sperrung Ihrer IP-Adresse führen kann.
Scraping Bild.de Bilder ohne Kodierung
Web-Scraping-Tools wie Octoparse haben sich als bemerkenswerte Tools etabliert, die mehr automatisierte Scraping-Optionen bieten und einen nutzerzentrierten Ansatz verfolgen. Leistungsstarke Plattformen machen Bild.de Scraping so nahtlos wie möglich und bieten eine einsteigerfreundliche und dennoch kompetente Umgebung für die Datenextraktion in Bild.de. Mit seinen fortschrittlichen Web-Scraping-Funktionen beseitigt Octoparse die Komplexität, die normalerweise mit der Datenextraktion verbunden ist.
Bei der Auswahl des richtigen Web-Scraping-Tools für Scraping-Projekte sind mehrere Schlüsselfaktoren zu berücksichtigen. So sind beispielsweise der Umfang und die Komplexität des Projekts ausschlaggebend für die Wahl. Wenn es sich um eine umfangreiche und komplizierte Aufgabe handelt, kann ein umfassenderes Tool wie Scrapy erforderlich sein. Andererseits sind Programmierkenntnisse eine weitere Überlegung. Während BeautifulSoup eine sanfte Lernkurve für Anfänger bietet, sind Tools wie Octoparse fantastisch für diejenigen, die sich mit der Programmierung nicht auskennen. Die Benutzerfreundlichkeit des Tools, seine Fähigkeit, dynamische Websites zu verarbeiten, und die Art der Daten, die Sie extrahieren möchten, sind weitere Faktoren, die berücksichtigt werden sollten. Für Websites wie Bild.de kann Octoparse mit seinem robusten integrierten Browser und der intelligenten Datenerkennung die Aufgabe vereinfachen. Lassen Sie uns nun näher darauf eingehen, wie Sie mit Octoparse Daten von Bild.de scrapen können.
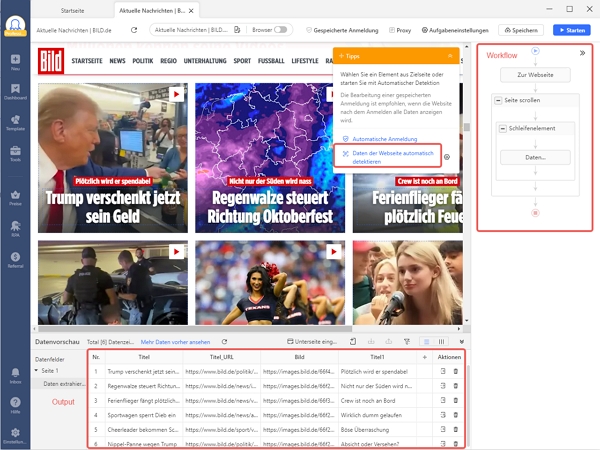
Wie man einen Bild.de Scraper in Octoparse erstellt
Schritt 1: Erstellen Sie eine neue Aufgabe zur Erfassung von Daten durch Bild.de
Kopiere die Bild.de-URL und füge sie in die Suchleiste von Octoparse ein. Klicken Sie dann auf „Starten“, um eine neue Scraping-Aufgabe zu erstellen.
Schritt 2: Erstellen und Ändern des Bild.de-Scrapers
Die Bild.de-Seite wird in den integrierten Browser von Octoparse geladen. Klicke auf „Webseiten-Daten automatisch erkennen“ im Tipps-Panel, nachdem die Seite fertig geladen ist. Alle extrahierbaren Daten werden auf der Seite grün hinterlegt, so dass Sie leicht überprüfen können, ob die gewünschten Daten ausgewählt sind oder nicht. Wenn Sie alle gewünschten Daten ausgewählt haben, erstellen Sie einen Workflow, indem Sie auf „Workflow erstellen“ klicken. Der Arbeitsablauf wird auf der rechten Seite angezeigt. Er enthält alle Aktionen des Vorgangs. Sie können auf jede einzelne Aktion klicken, um zu prüfen, ob sie wie geplant funktioniert. Sie können auch neue Aktionen hinzufügen oder unerwünschte Schritte aus diesem Flussdiagramm entfernen.
Schritt 3: Starten Sie den Bild.de Scraper
Wenn Sie alles durchgegangen sind, klicken Sie auf die Schaltfläche Ausführen, um den Bild.de Scraper zu starten. Sie können ihn je nach Bedarf lokal auf Ihrem Gerät oder per Fernzugriff über die Cloud ausführen. Schließlich exportieren Sie die Daten in lokale Dateien wie Excel und CSV oder in eine Datenbank wie Google Sheets, um sie nach der Ausführung weiter zu verwenden.
Mit Octoparse stehen Ihnen über 100 benutzerfreundliche Vorlagen zur Verfügung, um Daten schnell und einfach zu extrahieren. Darüber hinaus ermöglicht Ihnen die Octoparse-Vorlage die gezielte Extraktion der gewünschten Daten auf einfache Weise. Die Benutzerfreundlichkeit der Octoparse-Vorlage ist besonders hervorzuheben!
https://www.octoparse.de/template/t-online-nachrichten-scraper
Zusammenfassung
Insgesamt ist Bild.de eine unschätzbare Ressource für ein breites Spektrum von Nutzern. Seine vielfältigen Inhalte, die von persönlichen Essays bis hin zu professionellen Einblicken reichen, machen es zu einem interessanten Ziel für Data Scraping. Durch die Wahl eines geeigneten Web-Scraping-Tools können Nutzer das volle Potenzial von Bild.de für Marktanalysen, akademische Forschung, die Erstellung von Inhalten und die Formulierung von Geschäftsstrategien ausschöpfen. Ob BeautifulSoup für einfachere Aufgaben, Scrapy für komplexere Scraping-Bedürfnisse oder andere Web-Scraping-Software diese Tools sind der Schlüssel, um die Macht der Daten im heutigen digitalen Informationszeitalter zu nutzen.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



