Web Scraping ist eine Technik, damit man mit Programmiersprachen wie Scraping-Bots die Webdaten von einer oder mehreren Websites extrahieren könnte. Das Verhältnis zwischen Web Scraping und Extraktion der URLs ist auch nicht schwer zu verstehen. Web Scraping ist der Prozess der Verwendung von Bots, um Daten von einer Website zu extrahieren.
Für jeden, der eine relativ große Menge an Informationen von einer bestimmten Webseite in großen Mengen erhalten möchte, ist Web Scraping eine gute Wahl und kann den Zeit- und Arbeitsaufwand zur Erfüllung Ihrer Datenerfassungsanforderungen erheblich reduzieren.
Szenarien des Scraping von mehreren URLs
Wenn Sie sich für Web Scraping entscheiden, benötigen Sie wahrscheinlich viele Daten, die nicht einfach von der Website kopiert und eingefügt werden können. Die Vorgehensweisen zum Scrapen der Daten ist von Ihrem tatsächlichen Anwendungsfall abhängig. Es gibt im folgenden zwei Situationen:
1. Möglicherweise möchten Sie zahlreiche Informationen abrufen, die sich über mehrere Seiten einer bestimmten Website erstrecken.
Wenn Sie beispielsweise Produktinformationen aus E-Commerce wie Amazon abrufen, möchten Sie möglicherweise mehrere Seiten unter einer Kategorie oder Abfrage durchlaufen. Gleichzeitig werden diese Webseiten die ähnlichen Strukturen haben.
2. Möglicherweise möchten Sie einige Daten von ganz anderen Websites abrufen.
Ein aktuelles Beispiel wäre, wenn Sie möglicherweise öffentliche Informationen über Stellenangebote von den Karriereseiten verschiedener Unternehmen sammeln möchten. Außerdem besitzen diese Seiten eine gleiche Eigenschaft, die Webseite ist, sind sie eigentlich ganz anders. Oder es gibt ein anderes Beispiel, dass Sie Daten von mehreren Webseiten wie Nachrichten oder Finanzpublikationen aggregieren möchten. Sie können alle URLs für eine spätere Datenverarbeitung vorab sammeln.
Die Vorgehensweisen
Es gibt verschiedene Vorgehensweisen, um Daten aus mehreren URLs zu scrapen.
Programmersprache (Mit Koding)
Wenn Sie über einen technischen Hintergrund und gute Programmierkenntnisse verfügen, können Sie die Vorteile von BeautifulSoup, Scrapy und Selenium-ähnlichen Paketen nutzen, die in Python verfügbar sind, um Ihren eigenen Multi-URL-Scraper zu erstellen. Mit anderen Worten: Wenn Sie Programmiersprachen beherrschen, können Sie dies auch durch das Schreiben von Codes erreichen. Das Schreiben von Codes gibt Ihnen mehr Flexibilität und kann kompliziertere Situationen bewältigen. Aber das Schreiben von Skripten könnte für Nicht-Programmierer einschüchternd sein und auch für Entwickler eine große Arbeitsbelastung darstellen, wenn Sie mit vielen verschiedenen Webseiten arbeiten.
Web Scraping Tool (Ohne Koding)
Wenn Sie nicht mit der Programmierung vertraut sind oder überhaupt keine Erfahrung mit der Programmierung haben, können Sie das Web-Scraping mit Hilfe von No-Code Web Scraping Tools problemlos durchführen. Es gibt viele ähnliche Tools auf dem Markt wie Mozenda, Octoparse, Web Harvy, Parsehub, usw. Sie sind zwar alle generell programmiererfreundlich, aber die tatsächlichen Pakete, Funktionen und Preise können dennoch recht unterschiedlich sein. Um herauszufinden, welches Tool am besten zu Ihrem Unternehmen und Ihrem Budget passt, sehen Sie sich die 30 besten Web-Scraping-Tools in diesem Beitrag an.
Von den vielen Web-Scraping-Tools auf dem Markt empfehlen wir persönlich Octoparse – einen kostenlosen und leistungsstarken Web-Scraper, der Daten von jeder Website extrahieren kann. Octoparse wurde speziell für die skalierbare Datenextraktion verschiedener Datentypen entwickelt. Es kann URLs, Telefon, E-Mail-Adressen, Produktpreise, Bewertungen sowie Meta-Tag-Informationen und Fließtext durchsuchen. Darüber hinaus bietet Octoparse kostenlose vorgefertigte Scraping-Vorlagen, unbegrenzte Crawls, API-Integration, cloudbasierte Extraktion und vieles mehr. Werfen wir nun einen genaueren Blick darauf, wie es beim Scraping von mehreren URLs funktioniert.
Datenextraktion aus mehreren URLs mit Octoparse Template Mode
Die vorgefertigten Scraping-Vorlagen von Octoparse sind ideal für diejenigen, die die Lernkurve überspringen und sofort Daten von beliebten Webseiten wie Amazon, eBay, Twitter, YouTube, Gelbe Seiten, Otto, Immo Scout24, Stepstone und so weiter extrahieren möchten. Um Ihre Ziel zu verwirklichen, können Sie Octoparse herunterladen und schauen Sie, ob es eine Vorlage für Ihre Ziel-Website gibt (neue Vorlagen werden ständig erstellt und veröffentlicht).
Web Scraping mit vorgefertigten Scraping-Vorlagen könnte in 3 einfachen Schritten durchgeführt werden:
- Schritt 1: Wählen Sie „Task Templates“ aus dem Startbildschirm aus, und dann nehmen Sie eine gewünschte Vorlage. Jetzt klicken Sie auf „Try it“ zu starten.
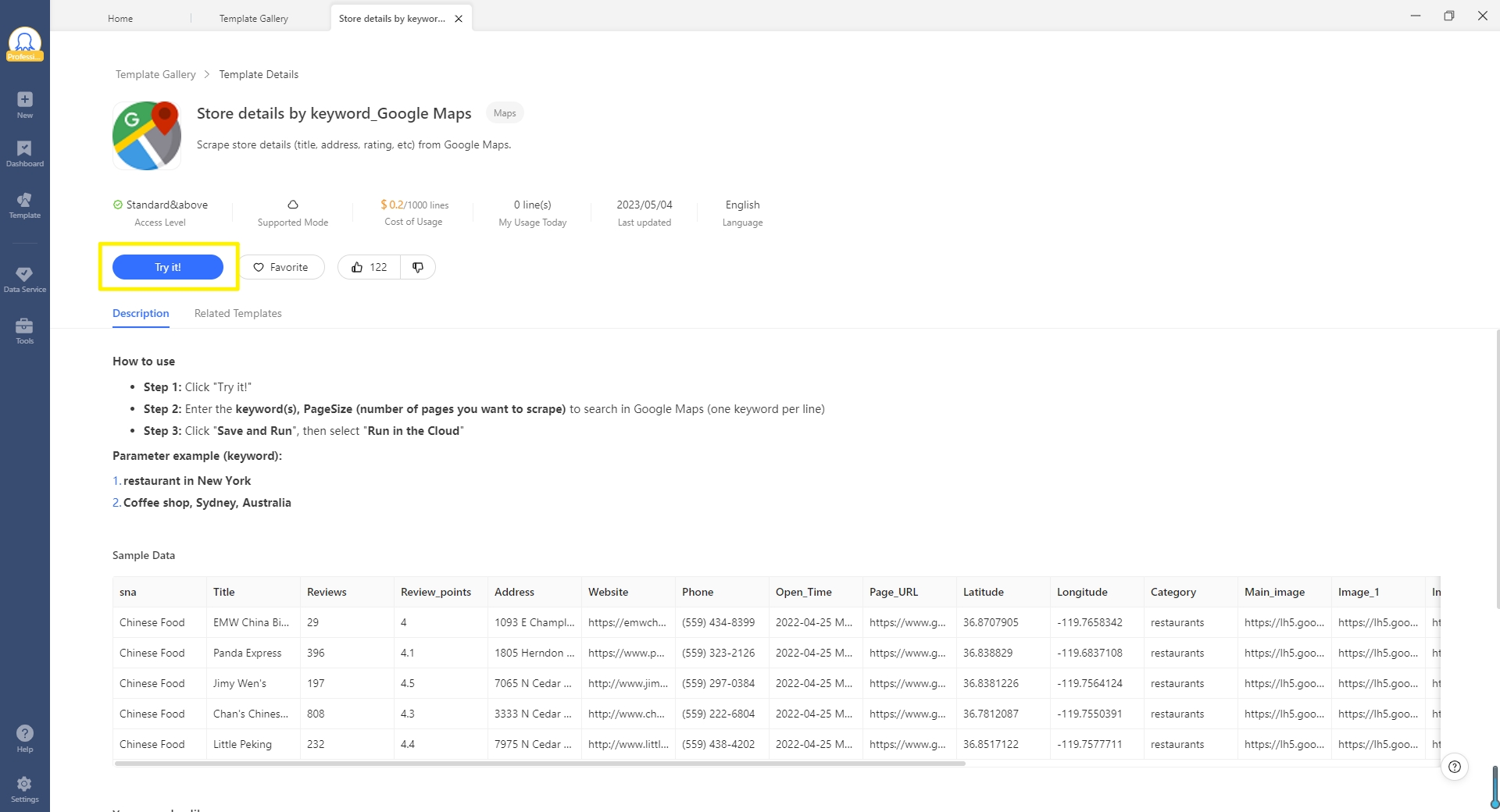
- Schritt 2: Geben Sie Seitenzahl und Schlüsselwörter, die bis zu 5 sind, in das Feld „Keyword“ ein.
Wenn Sie Daten über die erste Seite hinaus erfassen möchten, z.B. wenn Sie Daten von den ersten fünf Seiten extrahieren möchten, müssen Sie nicht die URLs der ersten fünf Seiten im Voraus scrapen, sondern geben Sie einfach „5“ als Seitenzahl in das Feld „PageSize“ ein. Jetzt haben Sie schon alles gestellt und können Sie loslegen.
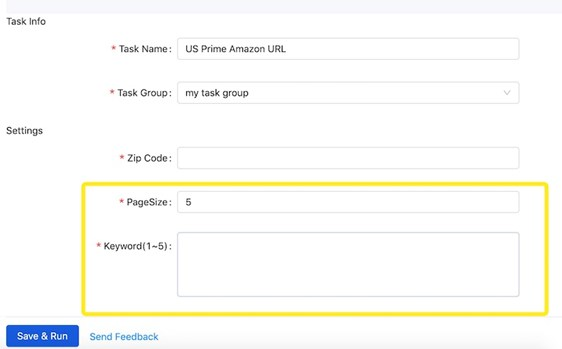
- Schritt 3: Wenn alle Felder korrekt ausgefüllt sind, klicken Sie auf „Save and Run“. Dann wird Octoparse sofort ausgeführt und gemäß Ihren Einstellungen die Daten extrahieren. Sie können den Auftragsfortschritt auf dem Dashboard überprüfen und die Daten in CSV, Excel, JSON oder HTMLherunterladen, wenn der Lauf abgeschlossen wäre.
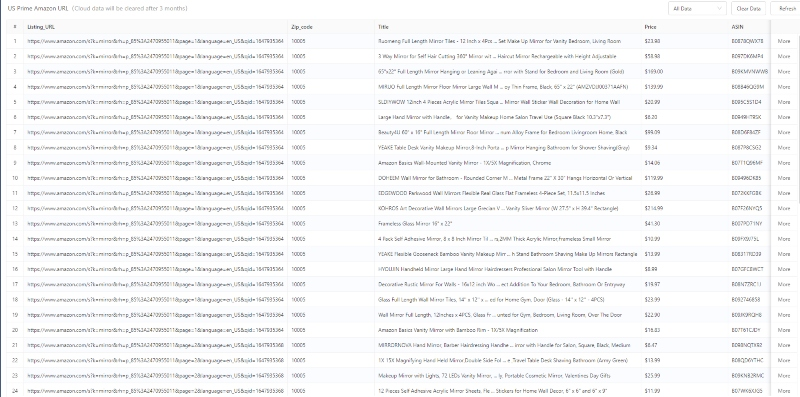
Hier sind die Daten, die mit der Vorlage gescrapt wurden. Starten Sie kostenlos, um Daten sofort zu erhalten!
Datenextraktion aus mehreren URLs mit Octoparse Advanced Mode
Der Advanced-Modus von Octoparse bietet mehr Flexibilität für den Umgang mit kundenspezifischen Datenanforderungen. Vielleicht möchten Sie beispielsweise Daten von einer Webseite extrahieren, die noch nicht in der Vorlage existiert. Oder in diesem Fall, wenn die Daten, die Sie benötigen, nicht mit den Vorlagen gescrapt werden können, können Sie mit dem erweiterten Moduser einen Crawler stellen, der auf Ihren Anwendungsfall zugeschnitten ist.
Selbst wenn Sie als Anfänger eine Aufgabe bauen, muss der Prozess nicht schwierig oder technisch sein. Seit der Version 8 hat Octoparse eine automatische Erkennungsfunktion eingeführt, die die Arbeit erheblich erleichtert hat. Schauen wir uns nun an, wie wir mit dem erweiterten Modus schnell eine Aufgabe erstellen können.
- Schritt 1: Klicken Sie auf den Button „+New“ in der Seitenleiste. Danach wählen Sie „Advanced Mode“, um eine neue Aufgabe zu erstellen.
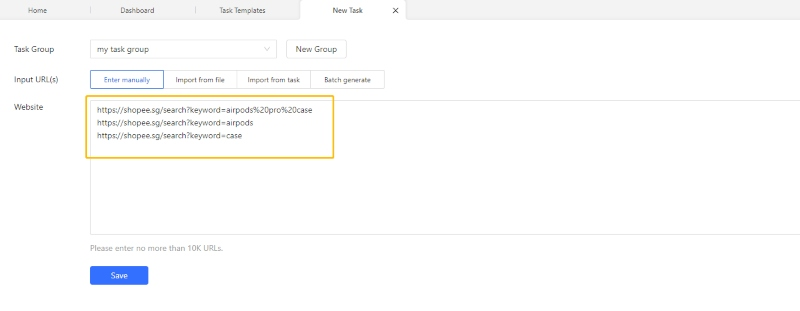
- Schritt 2: Kopieren Sie die Liste der URLs in das Textfeld und dann geben Sie sie in den Kasten ein. Danach klicken Sie auf „Save“. Octoparse wird automatisch einen Workflow erstellt.
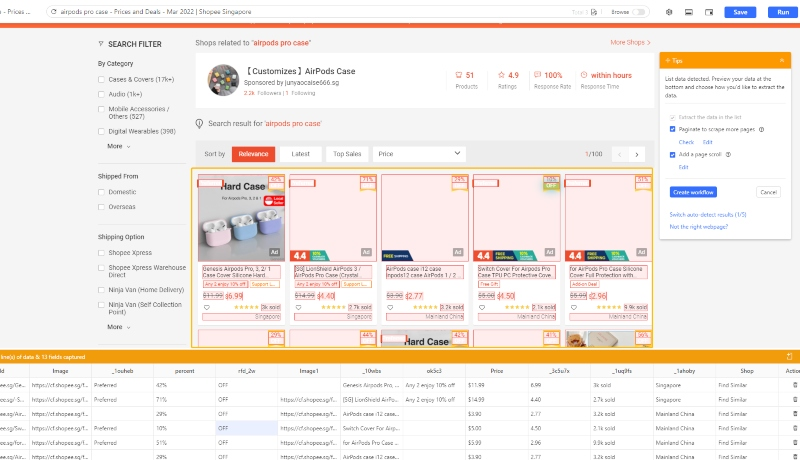
- Schirtt 3: Verwenden Sie die automatische Erkennungsfunktion, um den Scraping-Prozess zu starten, wenn die Seite fertig geladen ist. Der Scraper erkennt die Daten automatisch und „errät“, welche Daten Sie scrapen möchten.
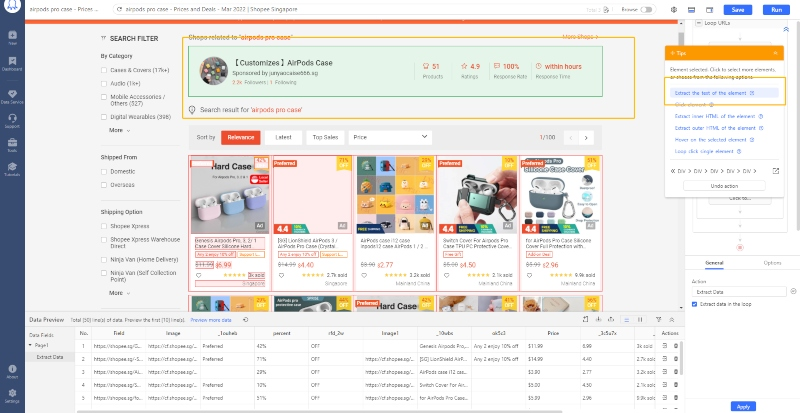
Wenn das „Raten“ nicht 100% genau ist, können Sie zwischen verschiedenen Datensätzen wechseln oder die Datenfelder zum Scrapen hinzufügen, indem Sie manuell auf die Webdaten klicken.
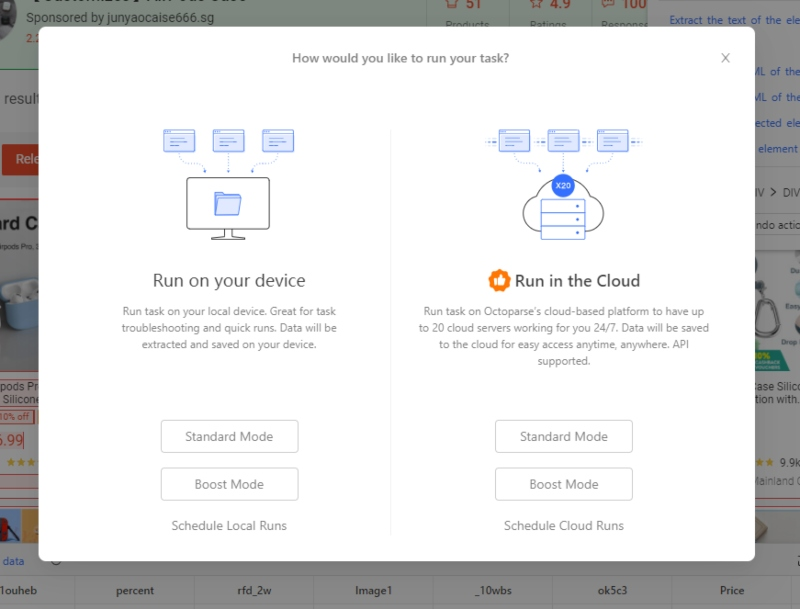
- Schritt 4: Nachdem Sie die Aufgabe eingerichtet haben, klicken Sie auf „Save“ und führen Sie die Aufgabe aus, um Ihre Daten zu erhalten! Sie können wählen, ob Sie die Aufgabe in der Lokale oder in der Cloud ausführen möchten.
Mit dem erweiterten Modus sind die Möglichkeiten buchstäblich endlos. Sie können Ihren eigenen Scraper für alle Arten von Websites erstellen und alle Daten abrufen, die Sie benötigen. Die obigen Schritte stellen nur eine stark vereinfachte Version des allgemeinen Prozesses dar, Sie können aber auch unser Schritt-für-Schritt-Tutorial lesen: Was ist Advanced Mode? Oder Sie können uns unter support@octoparse.com kontaktieren, wenn Sie Fragen oder Nachfrage haben.
Mit Octoparse stehen Ihnen über 500 benutzerfreundliche Vorlagen zur Verfügung, um Daten schnell und einfach zu extrahieren. Darüber hinaus ermöglicht Ihnen die Octoparse-Vorlage die gezielte Extraktion der gewünschten Daten auf einfache Weise. Die Benutzerfreundlichkeit der Octoparse-Vorlage ist besonders hervorzuheben!
https://www.octoparse.de/template/gelbe-seiten-listing-scraper-cloud
Zusammenfassung
Alles klar! Jetzt wissen Sie, wie Sie mit Octoparse Daten von mehreren URLs scrapen können. Wir hoffen wirklich, dass dieser Artikel Ihenn helfen können. Und vergessen Sie nicht, die Technik mit einigen anderen Websites zu versuchen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



