Fast jede Website, die wir heutzutage besuchen, ist in HTML geschrieben. HTML-Code enthält Text, Bilder, Links usw., die wir in einem Webbrowser sehen und lesen. Wenn Sie den HTML-Code einer beliebigen Website auslesen können, können Sie fast alles, was Sie auf einer Seite sehen wollen, mitnehmen. In diesem Beitrag zeigen wir Ihnen, wie Sie den HTML-Quellcode mit Octoparse auslesen und Elemente in HTML-Dateien finden können.
Was ist HTML?
HTML (HyperText Markup Language) ist die Standardauszeichnungssprache, die zur Erstellung und Gestaltung von Webseiten verwendet wird. Sie liefert die Struktur und den Inhalt für Webseiten und verwendet ein System von Tags und Attributen, um Elemente wie Überschriften, Absätze, Bilder, Links usw. zu definieren. Mit HTML können Entwickler organisierte und leicht zugängliche Inhalte erstellen, die von Browsern angezeigt werden können. Außerdem bildet es die Grundlage für ein ansprechendes und interaktives Web-Erlebnis.
Warum HTML-Scraping wichtig ist
Alles, was auf einer Website gelesen und gesehen wird, befindet sich in der HTML-Datei. HTML-Dateien werden für verschiedene Zwecke genutzt, wie Offline-Zugriff, Datenerhaltung, Inhaltsanalyse und Wiederverwendung von Inhalten. Das Scraping von HTML-Dateien ist daher eine nützliche, bequeme und effiziente Praxis.
Offline-Zugriff
Wenn Sie über HTML-Dateien verfügen, können Sie auf die Websites zugreifen, auch wenn Sie offline sind. Das Scraping von HTML-Dateien bietet Komfort und Flexibilität, die es Ihnen ermöglichen, ununterbrochenen Zugriff auf wichtige Informationen zu erhalten, um Website-Inhalte zu analysieren und Querverweise zu erstellen, ohne die Einschränkungen des Echtzeit-Browsing. Durch die Speicherung von HTML-Dateien auf Ihren lokalen Geräten können Sie außerdem wiederholte Online-Besuche vermeiden und so Bandbreite und Server-Ressourcen schonen.
Archivierung und Aufbewahrung von Daten
Websites ändern sich schnell, nicht nur der Inhalt der Seiten, sondern auch ihre Struktur. Wenn Sie eine Kopie des ursprünglichen Inhalts, wie er zu einem bestimmten Zeitpunkt auf den Websites erschien, speichern möchten, kann das Scraping von HTML Ihr bester Helfer sein. Es ermöglicht Ihnen, Archive von Webseiten zu erstellen und Inhalte zu bewahren, die sich im Laufe der Zeit ändern oder von den Live-Websites entfernt werden können. Solche Originalinhalte und -daten sind für Forschungs-, Überprüfungs- und Beweiszwecke wertvoll.
Inhaltsanalyse und Wiederverwendung
Daten auf Webseiten spielen seit Jahrzehnten eine wichtige Rolle bei der Inhaltsanalyse. Mit dem Scraping von HTML-Code können Sie die Struktur, die Metadaten und den Textinhalt von Webseiten untersuchen und diese Informationen für eine eingehende Inhaltsanalyse verwenden, die Erkenntnisse für die SEO-Optimierung, die Inhaltsprüfung und die Wettbewerbsanalyse liefern kann. Außerdem können Sie bestimmte Inhalte wie Text, Bilder, Links usw. extrahieren und wiederverwenden, um abgeleitete Werke, Zusammenfassungen oder Informationen für verschiedene Kontexte zu erstellen, nachdem Sie HTML-Dateien extrahiert haben.
Zweck der Ausbildung
Studierende, Entwickler und Lernende können vom Scraping von HTML-Quellcode profitieren. Entwickler können zum Beispiel gescrapte HTML-Dateien analysieren, um zu lernen, wie Browser Webseiten strukturieren und darstellen. Das ist eine großartige Gelegenheit für sie, ihre Programmierkenntnisse zu üben. Außerdem kann das Scraping von HTML-Code in verschiedenen Disziplinen wie Informatik, digitale Geisteswissenschaften, Sozialwissenschaften usw. angewandt werden, um die Zusammenarbeit zwischen den Studienfächern zu fördern. Studierende können Forschungsprojekte durchführen, Informationen aus verschiedenen Quellen sammeln und diese Daten analysieren, um die Ergebnisse in akademischen oder wissenschaftlichen Formaten zu präsentieren.
Je nach Bedarf können HTML-Dateien neben den oben genannten Aspekten auch in vielen anderen Bereichen hilfreich sein, z. B. bei der Webentwicklung, bei der Fehlersuche, bei Leistungstests usw. Ganz gleich, ob Sie in der Webentwicklung, der Erstellung von Inhalten oder im Marketing tätig sind, das Scraping von HTML-Code kann für Ihre Arbeit von grundlegender Bedeutung sein.
Scrapen von HTML-Quellcode mit Octoparse
Das Speichern einer Seite in einer HTML-Datei ist einfach. Sie müssen nur mit der rechten Maustaste auf die Seite klicken und „Speichern unter“ wählen. Aber Seiten auslesen und als HTML-Dateien in großen Mengen speichern? Das ist nicht so einfach. Hierfür benötigen Sie die Hilfe von Web Scraping Tools.
Octoparse ist eine No-Code-Lösung, mit der Sie den HTML-Code von Websites auslesen und in wenigen Minuten als Datei speichern können. Laden Sie Octoparse kostenlos herunter und installieren Sie es zunächst auf Ihrem Gerät. Melden Sie sich dann für ein neues Konto an oder melden Sie sich mit Ihrem Google- oder Microsoft-Konto an. Danach können Sie Ihre Reise zum Scrapen von HTML-Code mit den leistungsstarken Funktionen von Octoparse beginnen.
HTML Scraper – der müheloseste Weg
Um das Web Scraping zu vereinfachen und zu beschleunigen, wurden Octoparse Web Scraping Templates entwickelt, mit denen jeder ohne Einrichtungsaufwand Daten extrahieren kann. Octoparse bietet über 100 benutzerfreundliche Vorlagen, um Daten zu extrahieren. Mit Scrapern können Sie Daten von den beliebtesten Websites weltweit abrufen.
HTML Scraper ist eine Vorlage, die sich auf das Scrapen von HTML-Quellcode von Websites konzentriert. Über 30.000 Nutzer verwenden die Vorlagen. Beim Scrapen von HTML-Code müssen Sie eine Liste von URLs von Websites eingeben, die Sie als Dateien speichern möchten, und dann auf Start klicken. Danach erhalten Sie strukturierte Daten, darunter die ursprüngliche URL, den Seitentitel und den Quellcode.
https://www.octoparse.de/template/html-scraper
Erstellen Sie einen HTML-Code-Scraper in einfachen Schritten
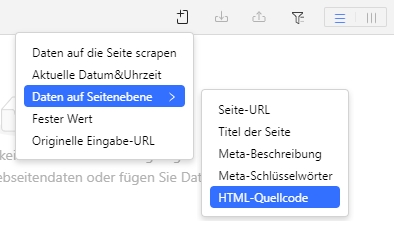
Octoparse vereinfacht auch den Prozess der Einrichtung benutzerdefinierter Scraper. Im Allgemeinen sind nur vier Schritte erforderlich, um mit Octoparse einen Scraper zu erstellen, der die gewünschten Daten von Websites extrahiert. Zusammen mit der automatischen Erkennungsfunktion und der künstlichen Intelligenz wird Ihre Effizienz beim Scrapen von Daten erhöht. Wenn Sie den HTML-Code Ihrer Zielseiten auslesen möchten, gehen Sie zum Datenvorschau-Panel am unteren Rand und klicken Sie auf Benutzerdefiniertes Feld hinzufügen > Daten auf Seitenebene > HTML-Quellcode. Danach können Sie den HTML-Code der Website abrufen.
Wie man gesuchte Elemente in HTML-Dateien abgleicht
Nun, jedes einzelne Wort in HTML-Dateien zu lesen, um die benötigten Elemente zu finden, ist zwar machbar, aber zeitaufwändig und mühsam. Keine Sorge, einige Tools können helfen, nicht benötigte Informationen zu entfernen und gewünschte Daten aus HTML-Dateien zu extrahieren.
Regulärer Ausdruck (RegEX)
Ein regulärer Ausdruck ist eine Folge von Zeichen, die ein Suchmuster definiert. Sie können ihn verwenden, um Zeichenketten innerhalb von Text auf der Grundlage bestimmter Muster oder Regeln in HTML-Dateien abzugleichen. Sie können zum Beispiel nahegelegene Zeichen verwenden, um die gewünschten Texte zu finden und RegEx schreiben, um bestimmte Informationen wie E-Mail-Adressen oder URLs aus HTML-Dateien zu extrahieren. Octoparse bietet auch ein kostenloses RegEx-Tool, um reguläre Ausdrücke für das Scraping von Daten zu generieren.
XPath
XPath (XML Path Language) ist eine Abfragesprache zur Auswahl von Knoten in XML-Dokumenten. Sie wird auch häufig verwendet, um durch Elemente und Attribute in HTML-Dokumenten zu navigieren. Sie können dieses Tool anwenden, um bestimmte Elemente anhand ihrer Struktur, ihrer Attribute oder ihres Inhalts zu finden. XPath ist besonders nützlich bei der Arbeit mit strukturierten Dokumenten wie HTML, in denen Elemente ineinander verschachtelt sind. Das Wichtigste ist, dass die XPath-Syntax einfach und leicht zu lesen und zu schreiben ist.
CSS-Selektor
CSS-Selektoren sind ebenfalls eine gute Wahl für die Extraktion von Webinhalten. Er wählt ein HTML-Element mit document.querySelector() aus und document.querySelectorAll () wählt eine Gruppe von HTML-Elementen mit denselben Eigenschaften aus. Die Syntax von CSS Selector ist der XPath-Syntax ähnlich. Allerdings unterstützen nicht alle Programmiersprachen eine CSS-Selektor-Bibliothek.
Zusammenfasung
HTML-Code ist wertvoll für die Datenanalyse. Das Scraping des HTML-Quellcodes von Websites kann das Rohmaterial liefern, das Sie für die Marktforschung benötigen, die zu datengestützten Entscheidungen und fundierteren Strategien beitragen wird. Testen Sie Octoparse jetzt, verwandeln Sie Websites in strukturierte Formulare und nutzen Sie den HTML-Code optimal.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



