„Können Sie Daten von Websites nach Excel ziehen?“
Möglicherweise haben Sie ähnliche Fragen wie oben, wenn Sie Daten von einer Website herunterladen möchten, da Excel ein einfaches und weit verbreitetes Tool zum Sammeln und Analysieren von Daten ist. Mit Excel können Sie problemlos einfache Aufgaben wie das Sortieren, Filtern und Gliedern von Daten und das Erstellen von Diagrammen auf der Grundlage dieser Daten erledigen. Wenn die Daten stark strukturiert sind, können wir mithilfe von Pivot- und Regressionsmodellen in Excel sogar erweiterte Datenanalysen durchführen.
Es ist jedoch eine äußerst mühsame Aufgabe, wenn Sie Daten manuell durch wiederholtes Eintippen, Suchen, Kopieren und Einfügen erfassen. Um dieses Problem zu lösen, listen wir auf 6 verschiedene Lösungen zum Scrapen von Websites nach Excel einfach und schnell.

Methode 1: No-Coding-Crawler zum Scrapen der Website nach Excel
Web Scraping ist die flexibelste Methode, um alle Arten von Daten von Webseiten in Excel-Dateien zu übertragen. Viele Benutzer haben Schwierigkeiten, weil sie keine Ahnung vom Programmieren haben. Ein einfaches Web Scraping-Tool wie Octoparse kann Ihnen jedoch dabei helfen, Daten von Webseiten ohne Programmieren in Excel zu übertragen.
Als einfacher Web Scraper bietet Octoparse automatische Erkennungsfunktionen auf Basis künstlicher Intelligenz, um Daten automatisch zu extrahieren. Sie müssen lediglich einige Änderungen überprüfen und vornehmen. Darüber hinaus verfügt Octoparse über erweiterte Funktionen wie API-Zugriff, IP-Rotation, Cloud-Datenextraktion und geplantes Scraping usw., damit Sie mehr Daten erhalten.

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.
Hier finden Sie eine Videoanleitung zum Extrahieren von Daten von jeder Website nach Excel. Nach dem Ansehen erhalten Sie einige Ideen. Oder Sie können den einfachen Schritten in den nächsten Teilen folgen, um Websitedaten ohne Codierung nach Excel zu extrahieren.
3 Schritte zum Scrapen von Daten aus einer Website in Excel 👉
✅ Schritt 1: Fügen Sie die URL der Ziel-Website ein, um die automatische Erkennung zu starten.
✅ Schritt 2: Erstellen und ändern Sie den Workflow
Nach der automatischen Erkennung wird ein Workflow erstellt. Sie können das Datenfeld einfach nach Ihren Bedürfnissen ändern. Es wird ein Tipps-Panel eingeblendet, und Sie können die darin enthaltenen Hinweise befolgen.
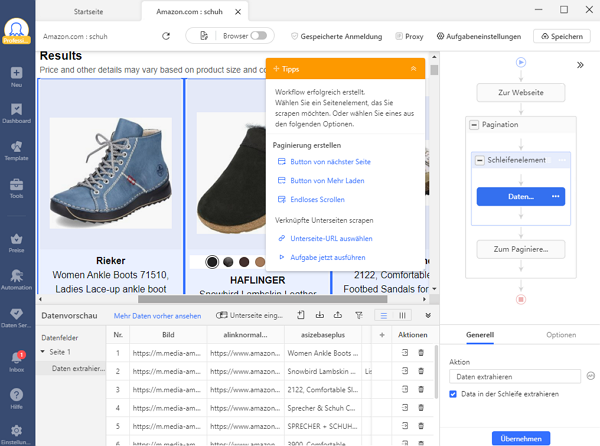
✅ Schritt 3: Herunterladen der gescrapten Website-Daten in Excel
Führen Sie die Aufgabe aus, nachdem Sie alle Datenfelder überprüft haben. Sie können die gescrapten Daten schnell im Excel/CSV-Format auf Ihr lokales Gerät herunterladen oder in einer Datenbank speichern.
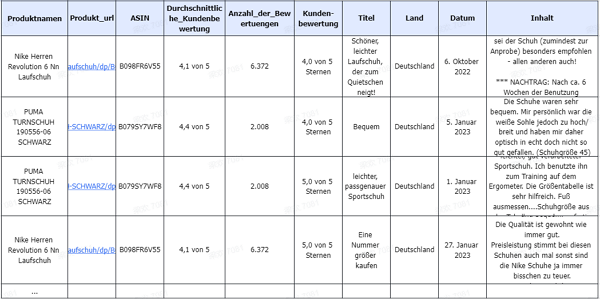
Methode 2: Extraktion mit Aufgabenvorlagen
Als einfacher Web Scraper bietet Octoparse automatische Erkennungsfunktionen, die auf KI basieren, um Daten automatisch zu extrahieren. Was Sie tun müssen, ist einfach zu überprüfen und einige Änderungen vorzunehmen. Sie können auch die voreingestellten Daten-Scraping-Vorlagen für beliebte Websites wie Amazon, eBay, LinkedIn, Google Maps usw. verwenden, um die Webseitendaten mit wenigen Klicks zu erhalten. Probieren Sie die untenstehende Online-Scraping-Vorlage aus, ohne eine Software auf Ihre Geräte herunterzuladen.
https://www.octoparse.de/template/email-social-media-scraper
✅ Schritt 1: Wählen Sie eine Vorlage für Web Scraping
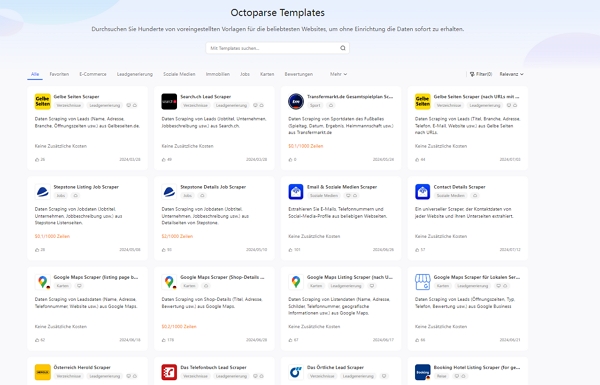
✅ Schritt 2: Verwenden Sie die Vorlage
✅ Schritt 3: Klicken Sie auf “Versuchen” und beginnen Sie mit der Extraktion
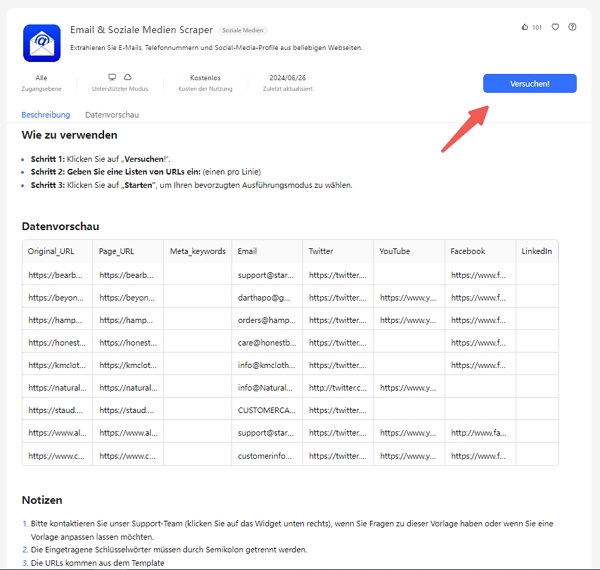
Nachdem Sie mit Octoparse Daten gesammelt haben, müssen Sie diese möglicherweise in Excel verarbeiten. Damit Sie die neuen Funktionen von Excel optimal nutzen können, finden Sie hier eine ausführliche Anleitung mit einigen nützlichen Hinweisen und Tipps.
Methode 3: Mithilfe von Excel Web Queries, Daten aus Website auszulesen
Im Vergleich zu der durch Kopieren und Einfügen manuell umwandelnden Transformation von Webdaten kann man mit Excel Web Queries (Englisch) schnell Daten einer Webseite in ein Excel-Arbeitsblatt umwandeln. Es kann automatisch Tabellen erkennen, die in den HTML-Code der Webseite eingebettet sind. Excel Web Queries können auch verwendet werden, wenn eine Standard-ODBC (Open Database Connectivity) Verbindung schwer zu erstellen oder zu pflegen ist. Mit Excel Web Queries können Sie direkt Tabellen von beliebigen Webseiten scrapen.
Den Prozess kann man in einigen einfachen Schritten zusammenfassen:
✅ Schritt 1: Gehen zu Daten > Externe Daten erhalten> Aus dem Web
✅ Schritt 2: Ein Browser-Fenster mit dem Namen “Neue Web Query” wird angezeigt
✅ Schritt 3: Geben Sie in die Adressleiste die Webadresse ein.
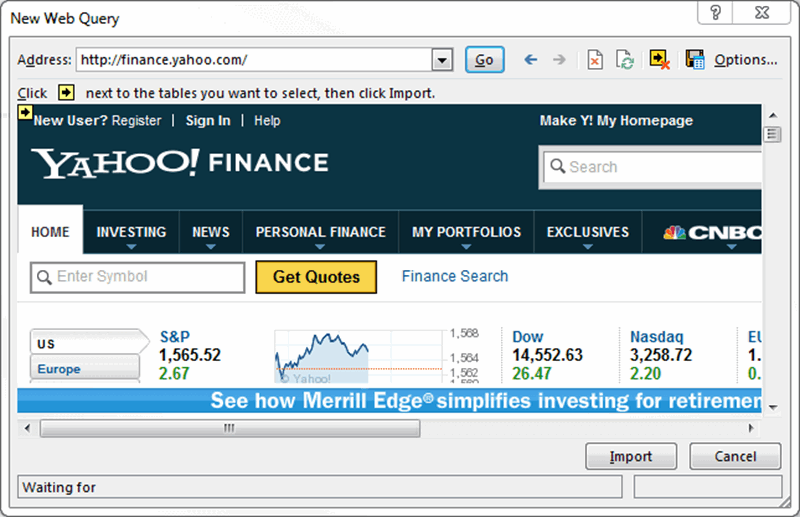
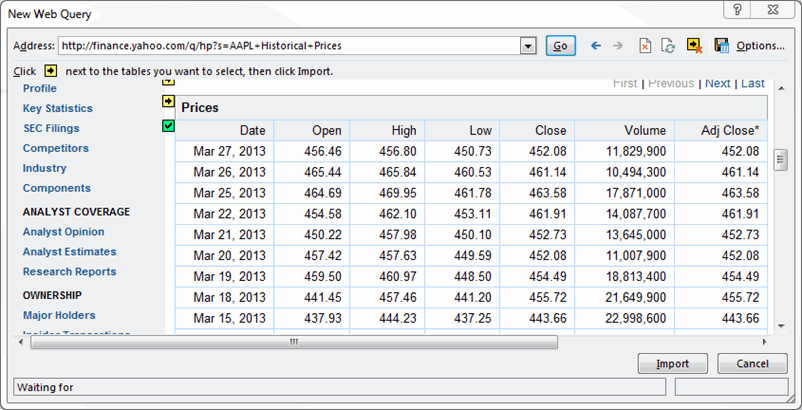
✅ Schritt 4: Die Webseite wird geladen und zeigt gelbe Symbole von Daten/Tabellen an.
✅ Schritt 5: Wählen Sie das entsprechende Symbol aus.
✅ Schritt 6: Drücken Sie den Button „Importieren“.
Jetzt haben Sie die Webdaten zum Excel-Arbeitsblatt gescrapt, die perfekt in Zeilen und Spalten wie gewünscht angeordnet werden.
Methode 4: Mithilfe von Excel VBA, Daten aus Website zu extrahieren
Man verwendet Formeln in Excel (z.B. =avg(…), =sum(…), =if(…), usw.) oft , aber die meisten sind weniger vertraut mit der eingebauten Sprache – Visual Basic for Application (VBA). Es ist allgemein als „Makros“ bekannt und solche Excel-Dateien werden als **.xlsm gespeichert. Bevor Sie die Sprache verwenden, müssen Sie zuerst den Tab „Developer“ in der Multifunktionsleiste aktivieren (Rechtsklick auf Datei -> Multifunktionsleiste anpassen -> Tab „Developer“ aktivieren). Richten Sie dann Ihr Layout ein. In diesem Entwickler-Interface können Sie VBA-Code schreiben, der verschiedene Ereignisse befestigen kann. Klicken Sie HIER, um mit VBA eine Aufgabe in excel 2010 zu beginnen.
Die Verwendung von Excel VBA wird ein bisschen komplizierter – das ist nicht so benutzerfreundlich für die Nicht-Programmierer. VBA funktioniert durch die Ausführung von Makros und Schritt-für-Schritt-Prozeduren, die in Excel Visual Basic geschrieben sind. Um mit VBA Daten von Webseiten zu scrapen, müssen wir manche VBA-Skripts vorbereiten, um Anfragen an Webseiten zu senden und die zurückgegebenen Daten von diesen Webseiten zu erhalten. Es ist üblich, VBA mit XMLHTTP und regulären Ausdrücken zu verwenden, um die Webseiten zu parsen. Mit Windows-Betriebssystem können Sie VBA mit WinHTTP oder InternetExplorer zusammmen verwenden, um Daten von Webseiten zu Excel zu scrapen.
Mit Geduld und Übungen können Sie Excel-VBA-Code und HTML-Kenntnisse beherrschen. Und es lohnt sich, die Sprache zu erlernen, weil sie das Web-Scraping zu Excel viel einfacher und effizienter machen kann und die wiederholende Arbeit automatisieren lässt. Es gibt viele Materialien und Foren, in denen Sie lernen können, wie man VBA-Code schreiben sollte.
Methode 5: Mithilfe von Web Scraping Services, Daten aus Website abzurufen
Wenn Zeit für Sie am wichtigsten ist und Sie sich auf Ihr Kerngeschäft konzentrieren möchten, wäre es die beste Wahl, dem professionellen und erfahrenden Web-Scraping-Team solch komplizierte Web-Scraping-Arbeiten auszulagern. Es ist schwierig, Daten von Webseiten zu scrapen, weil Anti-Scraping-Bots von manchen Webseiten das Web-Scraping einschränkt. Ein kompetentes Web-Scraping-Team können Ihnen dabei helfen, Daten von Webseiten auf korrekte Art und Weise zu extrahieren und Ihnen strukturierte Daten in einer Excel-Tabelle oder in einem beliebigen Format zu senden. Octoparse bietet maßgeschneiderte Crawler-Anpassungsdienste an, bei denen ein individueller Crawler gemäß Ihren spezifischen Anforderungen eingerichtet wird. Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Methode 6: Daten von einer Webseite mit Python
Um Daten von einer Webseite mithilfe von Microsoft Excel und Python zu scrapen, können Sie das requests-Modul (zum Abrufen der Webseite), BeautifulSoup (zum Parsen der HTML-Inhalte) und pandas (zum Erstellen und Speichern der Daten in einer Excel-Datei) verwenden. Stellen Sie sicher, dass Sie die Bibliotheken zuerst installiert haben:
Hier ist ein Beispielskript, das zeigt, wie das Scraping und die Speicherung in Excel funktioniert:
Zusammenfassung
Es gibt 6 Möglichkeiten, wie sich die Extraktion von Daten aus Websites und der Import in Excel automatisieren lassen, um Zeit zu sparen und die Effizienz zu steigern. Durch die Verwendung von Excel-Webabfragen, VBA-Programmierung, automatisierten Web-Crawling-Tools oder professionellen Web-Crawling-Diensten können Benutzer Webdaten leicht in strukturierte Informationen umwandeln, um Datenanalyse- und Verarbeitungsprozesse zu optimieren.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



