Web Scraping ist in den letzten Jahren zu einem heißen Thema geworden. Immer mehr Menschen haben die Bedürfnisse, Daten von verschiedenen Websites zu extrahieren, um ihre Geschäftsentwicklung zu unterstützen. Beim Web-Scraping treten jedoch viele Herausforderungen auf, wie z. B. Sperrmechanismen, die den Zugriff auf Daten behindern können. Schauen wir uns die Herausforderungen im Detail an.
1. Bot-Zugang
Prüfen Sie zunächst, ob Ihre Ziel-Website Scraping zulässt, bevor Sie damit beginnen. Wenn Sie feststellen, dass die robots.txt einer Website das Scraping nicht zulässt, können Sie den Eigentümer der Website um die Erlaubnis bitten, indem Sie ihm Ihren Bedarf und Ihre Ziele erläutern. Wenn der Eigentümer immer noch nicht einverstanden ist, wäre es besser, eine alternative Website zu finden, die ähnliche Informationen enthält.
2. Strukturen der Webseiten
Die meisten Webseiten basieren auf HTML (Hypertext Markup Language). Die Designer von Webseiten können ihre eigenen Standards für die Gestaltung der Seiten haben, sodass die Strukturen von Webseiten sehr unterschiedlich sind. Wenn Sie mehrere Websites scrapen möchten, müssen Sie für jede Website einen Scraper erstellen.
Außerdem aktualisieren Websites regelmäßig ihren Inhalt, um die Benutzerfreundlichkeit zu verbessern oder neue Funktionen hinzuzufügen, was häufig zu strukturellen Änderungen auf der Webseite führt. Da Web-Scraper auf ein bestimmtes Design der Seite eingestellt sind, würden sie für die aktualisierte Seite nicht funktionieren. Manchmal erfordert sogar eine kleine Änderung auf der Zielseite eine Anpassung des Scrapers.
Octoparse hat einen benutzerdefinierten Workflow, um menschliches Verhalten zu simulieren, damit Sie mehrere Seiten scrapen können.
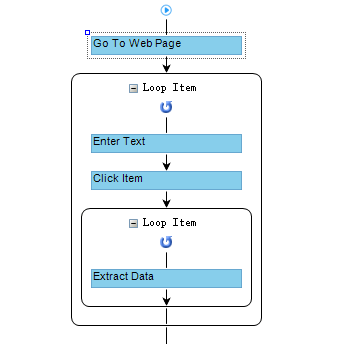
3. IP-Sperrung
Die IP-Sperrung ist eine gängige Methode, um Web-Scraper vom Zugriff auf Daten einer Website zu verhindern. Wenn eine Website viele Anfragen von derselben IP-Adresse feststellt, kann die Website die IP-Adresse entweder vollständig sperren oder ihren Zugang einschränken, um den Scraping-Prozess zu stoppen.
Es gibt viele IP-Proxy-Dienste wie Luminati, die in automatisierte Scraper integriert werden können, um Menschen vor solchen Blockierungen zu schützen.
Die Octoparse Cloud-Extraktion nutzt mehrere IPs, um eine Website gleichzeitig zu scrapen, damit eine IP nicht zu viele Anfragen stellt, und die Geschwindigkeit beim Web-Scraping auch deutlich erhöht.
4. CAPTCHA
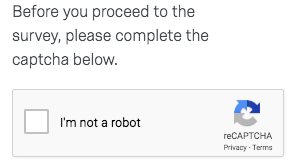
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) wird häufig verwendet, um Menschen von Scraping-Tools zu unterscheiden, indem Bilder oder logische Probleme angezeigt werden, die für Menschen leicht zu lösen sind, für Scraper jedoch nicht.
Viele CAPTCHA-Löser können in Bots implementiert werden, um ein ununterbrochenes Scraping zu gewährleisten. Obwohl die Technik zur Überwindung von CAPTCHA praktisch ist, könnten sie den Scraping-Prozess immer noch ein wenig verlangsamen.
5. Honigtopf-Fallen
Ein Honeypot ist eine Falle, die der Website-Besitzer auf der Seite platziert, um Scraper zu fangen. Die Fallen können Links sein, die für Menschen unsichtbar, für Scraper aber sichtbar sind. Sobald ein Scraper in die Falle tappt, kann die Website die erhaltenen Informationen (z. B. die IP-Adresse) nutzen, um den Scraper zu blockieren.
Octoparse verwendet XPath, um die zu klickenden oder zu scrapenden Elemente genau zu lokalisieren, was die Gefahr, in die Falle zu tappen, reduziert.
6. Langsame Ladegeschwindigkeit
Websites können langsam reagieren oder sogar nicht laden, wenn sie zu viele Zugriffsanfragen erhalten. Das ist kein Problem für Menschen, denn sie können die Webseite neu laden und warten, bis die Website wieder funktioniert. Aber beim Scrapen kann es zu Problemen kommen, da der Scraper nicht weiß, wie er mit solchem Notfall umgehen soll.
Octoparse ermöglicht es den Benutzern, einen erneuten Ladevorgang einzurichten, wenn bestimmte Bedingungen erfüllt sind. Es kann sogar benutzerdefinierte Workflow in voreingestellten Situationen ausführen.
7. Dynamischer Inhalt
Viele Websites verwenden AJAX, um dynamische Webinhalte zu aktualisieren. Beispiele dafür sind das langsame Laden von Bildern, unendliches Scrollen und die Anzeige weiterer Informationen durch Anklicken einer Schaltfläche über AJAX-Aufrufe. Für die Nutzer ist es bequem, mehr Daten auf solchen Websites zu sehen, aber für Scraper ist es nicht so.
Octoparse kann diese Websites mit verschiedenen Funktionen wie Scrollen auf der Seite oder AJAX-Laden leicht scrapen.
8. Anmeldung erforderlich
Für einige geschützte Informationen müssen Sie sich möglicherweise erst anmelden. Nachdem Sie Ihre Anmeldedaten eingegeben haben, fügt Ihr Browser den Cookie-Wert automatisch an mehrere Anfragen an, die Sie auf den meisten Websites stellen, sodass die Website weiß, dass Sie dieselbe Person sind, die sich gerade zuvor angemeldet hat. Achten Sie also beim Scraping der Websites, die eine Anmeldung erfordern, darauf, dass Cookies mit den Anfragen gesendet wurden.
Octoparse kann Nutzern einfach dabei helfen, sich bei einer Website einzuloggen und die Cookies zu speichern, genau wie ein Browser.
9. Web Scraping in Echtzeit
Das Scraping von Daten in Echtzeit ist für Preisvergleiche, Bestandsverfolgung usw. unerlässlich. Die Daten können sich schnell ändern und einem Unternehmen große Kapitalgewinne bescheren. Der Scraper dafür soll die Websites die ganze Zeit überwachen und Daten scrapen. Trotzdem kommt es zu einer gewissen Verzögerung, da die Abfrage und die Lieferung der Daten Zeit brauchen. Außerdem ist es auch eine große Herausforderung, eine große Menge an Daten in Echtzeit zu erfassen.
Die geplante Cloud-Extraktion von Octoparse kann Websites in einem Mindestintervall von 5 Minuten scrapen, um ein Scraping nahezu in Echtzeit zu erreichen.
In Zukunft wird es sicherlich noch mehr Herausforderungen beim Web-Scraping geben, aber der Grundsatz für Scraping ist immer derselbe: Behandeln Sie die Websites freundlich. Versuchen Sie nicht, sie zu überlasten. Außerdem können Sie immer ein Web-Scraping-Tool oder einen Dienst wie Octoparse finden, der Ihnen beim Web-Scraping helfen kann. Mit Octoparse stehen Ihnen über 100 benutzerfreundliche Vorlagen zur Verfügung, um Daten schnell und einfach zu extrahieren. Darüber hinaus ermöglicht Ihnen die Octoparse-Vorlage die gezielte Extraktion der gewünschten Daten auf einfache Weise. Die Benutzerfreundlichkeit der Octoparse-Vorlage ist besonders hervorzuheben.
Zusammenfassung
Dieser Artikel befasst sich mit neun Herausforderungen, die beim Crawling von Webseiten auftreten können, z. B. IP-Blockierung, CAPTCHA-Validierung, dynamische Inhalte und Änderungen der Seitenstruktur. Es wird beschrieben, wie diese Probleme durch den Einsatz von Tools wie Octoparse gelöst werden können, damit Benutzer das Crawling von Daten effizienter durchführen können, wobei betont wird, dass Websites freundlich behandelt werden sollten, um ihren Betrieb nicht zu stören.
Hier bekommen Sie Octoparse! 🤩
Preis: $0~$249 pro Monat
Packet & Preise: Octoparse Premium-Preise & Verpackung
Kostenlose Testversion: 14-tägige kostenlose Testversion
Herunterladen: Octoparse für Windows und MacOs
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬
Autor*in: Das Octoparse Team ❤️

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



