Das Aufkommen von „Web Scraping Tools“ wie Octoparse hat dazu geführt, dass Web Scraping in vielen Bereichen eingesetzt wird. Obwohl Scraping an sich nicht illegal ist, verbieten einige Websites in ihren Nutzungsbedingungen die Verwendung von Web Scraping.
In solchen Fällen stellen sich viele Menschen Fragen wie „Wie kann ich Web-Scraping betreiben, ohne entdeckt zu werden?“ Viele Menschen stellen sich Fragen wie „Wie kann ich Web-Scraping betreiben, ohne entdeckt zu werden? In diesem Artikel werden daher fünf Maßnahmen erläutert, die verhindern, dass Scraping entdeckt wird.
Web Scraping ist eine wertvolle Methode zur Datengewinnung, aber wie verhindern Sie, dass Websites Sie blockieren? In diesem Artikel erfahren Sie die besten Anti-Crawl-Strategien, um sicher und effizient zu bleiben.
Wenn Sie Bedenken haben, Web Scraping einzusetzen, lesen Sie bitte auch diesen Artikel.
Ist Scraping illegal? 10 häufige Missverständnisse über Web Scraping.
Was ist Scraping?
Scraping ist eine Technologie zur automatischen Extraktion von Daten von Websites, die es ermöglicht, große Informationsmengen schnell zu sammeln, die manuell nicht erfasst werden können. So lassen sich effizient Daten wie Produktpreise, Bewertungen und Wettbewerbstrends sammeln.
Vereinfacht gesagt nutzt Scraping ein Programm, um den Inhalt einer Website automatisch zu kopieren. Jedoch kann Web-Scraping technische Probleme und rechtliche Risiken mit sich bringen, wenn es unsachgemäß durchgeführt wird.
Es besteht die Gefahr, dass die Server der betroffenen Parteien überlastet werden, was im schlimmsten Fall zu Ausfällen führen kann. Solche Ausfälle, die den Geschäftsbetrieb beeinträchtigen, könnten zu Schadensersatzforderungen oder Anklagen wegen Geschäftsstörung führen.
Aus diesem Grund haben Website-Betreiber Anti-Scraping-Technologien implementiert, um das Scraping zu verhindern und zu erschweren.
Vorteile des Scrapings
Scraping hat eine Reihe von Vorteilen. Dazu gehören insbesondere.
Effizienz der Datenerfassung
Der größte Vorteil des Scraping ist die Effizienz bei der Datenerfassung. Was man manuell viel Zeit und Mühe kostet, lässt sich mit einem Scraping-Tool automatisch und schnell erledigen. Beispielsweise ist es unpraktisch, Preisinformationen für zahlreiche Produkte einzeln zu überprüfen. Mit Scraping erhalten Sie jedoch alle benötigten Daten in wenigen Minuten, was eine schnelle Entwicklung von Marketingstrategien und einen Wettbewerbsvorteil ermöglicht.
Sie können Daten erhalten, die APIs nicht freigeben
Viele Webdienste bieten APIs an, aber nicht alle Daten können über APIs abgerufen werden. Mit Scraping können Sie Daten abrufen, die von APIs nicht bereitgestellt werden.
Mit Scraping können beispielsweise Informationen gesammelt werden, die nicht über APIs abgerufen werden können, wie z. B. detaillierte Bewertungen bestimmter Produkte oder Nutzerkommentare. Auf diese Weise lassen sich umfangreichere Datensätze für anspruchsvollere Analysen und Erkenntnisse nutzen.
Umfassende Nutzung in Wirtschaft und Forschung
Scraping ist in Wirtschaft und Forschung weit verbreitet. Es wird z. B. für Wettbewerbsanalysen, Marktforschung, SEO und viele andere Anwendungen genutzt.
In der akademischen Forschung ist Scraping ebenfalls sehr nützlich für die Sammlung und Analyse von Daten in großem Umfang. Die schnelle Sammlung und Analyse von Daten kann die Entscheidungsfindung in Unternehmen unterstützen und die Genauigkeit der Forschung verbessern.
Nachteile des Scrappings
Das Scrapen hat zwar viele Vorteile, aber auch Nachteile. Die wichtigsten Nachteile sind im Folgenden aufgeführt.
Zugriffsverweigerung
Beim Scraping können Sie auf Zugriffsverweigerungen seitens der Websites stoßen, da viele von ihnen Bots erkennen und blockieren, um die Serverlast zu reduzieren. Beispiele hierfür sind das Blockieren von IP-Adressen und die Nutzung von CAPTCHAs, was den kontinuierlichen Datenabruf erschwert. Gegenmaßnahmen wie eine reduzierte Zugriffshäufigkeit und die Verteilung von IP-Adressen haben jedoch ihre Grenzen, was es schwierig macht, diese Probleme vollständig zu umgehen.
Zeitaufwändiger Technologieerwerb
Für effektives Scraping ist ein gewisses Maß an technischem Geschick erforderlich. Anfänger, die mit Scraping beginnen wollen, benötigen Grundkenntnisse in Programmierung, HTML und CSS.
Sie benötigen auch die Fähigkeit, Skripte zu erstellen, um mit den unterschiedlichen Strukturen verschiedener Websites zurechtzukommen und Zugangsbeschränkungen zu umgehen. Das Erlernen von Scraping erfordert also Zeit und Mühe, und es kann schwierig sein, es in kurzer Zeit umzusetzen.
Rechtliche Risiken
Es ist wichtig zu bedenken, dass Scraping rechtliche Risiken birgt. Viele Websites verbieten in ihren Nutzungsbedingungen die unbefugte Beschaffung von Daten, was bei Zuwiderhandlung zu rechtlichen Problemen führen kann.
Insbesondere bei der Verwendung von Daten für kommerzielle Zwecke besteht ein erhöhtes Risiko von Urheberrechtsverletzungen und Verstößen gegen das Gesetz über unerlaubten Zugang. Daher ist es beim Scraping wichtig, die Nutzungsbedingungen der Ziel-Website zu prüfen und sich über die rechtlichen Risiken im Klaren zu sein, bevor man fortfährt.
Wie kann Scraping aufgedeckt werden?
Einige Websites haben absichtlich Mechanismen eingebaut, um Scraping zu blockieren. Der Grund dafür ist, dass beim Scraping eine große Anzahl von Anfragen in kurzer Zeit gesendet wird, was den Server überlasten und zu Ausfallzeiten führen kann, und auch, weil sie nicht wollen, dass die auf der Website verarbeiteten Daten ohne ihre Erlaubnis entwendet werden.
Es gibt zwei Hauptmethoden, um Scraping zu verhindern
- CAPTCHAs
- Blockierung der IP-Adresse
| Technik | Erklärung | Schutzmöglichkeit |
| CAPTCHA | Benutzererkennung durch Tests | Automatisierte Lösungstools |
| IP-Blocking | Blockieren verdächtiger IPs | Nutzung von Rotating Proxies |
CAPTCHA ist eine Methode, mit der anhand von Bildern oder Text festgestellt werden kann, ob eine Website von einem Menschen oder einem Computer aufgerufen wird. Zu den bekanntesten Diensten gehört reCAPTCHA von Google.
Die IP-Adressensperre ist eine Methode, mit der der Zugriff von einer IP-Adresse aus blockiert wird, wenn innerhalb eines kurzen Zeitraums eine große Anzahl von Anfragen von derselben IP-Adresse aus festgestellt wird. Diese Methoden werden eingesetzt, um die Bedrohung durch Scraping und die damit verbundenen Risiken zu verhindern.
Was passiert, wenn das Schaben aufgedeckt wird?
Wenn Sie beim Scraping erwischt werden, kann das folgende Konsequenzen haben
- Eingeschränkter Zugang: Der Eigentümer der Website kann Ihre IP-Adresse oder Ihren Benutzer-Agenten sperren, wenn er Scraping entdeckt. Dadurch kann Ihr Zugang zu dieser Website eingeschränkt werden.
- Rechtliche Schritte: Wenn eine Website Scraping als illegal ansieht, kann sie rechtliche Schritte einleiten. Dies kann Verwarnungen und rechtliche Schritte umfassen. Insbesondere das Scraping von persönlichen Informationen oder urheberrechtlich geschützten Inhalten kann zu ernsthaften rechtlichen Problemen führen.
- Rufschädigung: Wenn Sie beim Scraping erwischt werden, kann Ihr Ruf unter ethischen Gesichtspunkten geschädigt werden. Insbesondere der Missbrauch personenbezogener Daten oder der unbefugte Zugriff auf Informationen von Konkurrenten kann zu einem Verlust an Glaubwürdigkeit und Vertrauen in das Unternehmen führen.
5 Wege und Maßnahmen, um zu verhindern, dass jemand von Ihrem Scraping erfährt
Da Sie nun wissen, warum Scraping blockiert wird, finden Sie hier einige Möglichkeiten, wie Sie verhindern können, dass die andere Partei von Ihrem Scraping erfährt. Dies wird Ihnen helfen, wenn Ihr Scraping aufgedeckt wird.
1. Verlangsamung des Scraping-Prozesses
Die meisten Web Scraping-Aufgaben zielen darauf ab, Daten so schnell wie möglich abzurufen. Natürlich ist die Geschwindigkeit, mit der Menschen auf eine Website zugreifen, im Vergleich zum Web Scraping langsamer.
Anhand der Zugriffsgeschwindigkeit kann die Website daher feststellen, ob der Zugriff von einem Web Scraper stammt oder nicht. Ist der Zugriff zu schnell, besteht der Verdacht, dass es sich um einen Web Scraper handelt, und der Zugriff wird blockiert.
Mit anderen Worten, es ist wichtig, die Website nicht zu überlasten: Lassen Sie sich Zeit für die Zugriffsanfrage des Web Scrapers und scrapen Sie mit der niedrigstmöglichen Geschwindigkeit. Wenn Sie behutsam vorgehen, ohne den anderen Server zu überlasten, können Sie sicherstellen, dass das Scrapen weitergeht.
Mit Octoparse können Sie die Geschwindigkeit des Scrapings steuern, indem Sie die Wartezeit für die einzelnen Schritte des Arbeitsablaufs festlegen. Es ist auch möglich, „zufällig“ zu wählen, um eine humanere Ausführung des Scrapings zu erreichen.
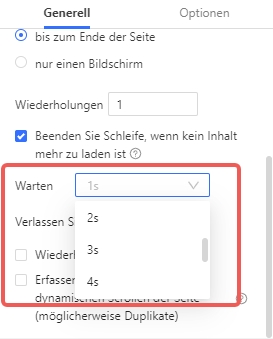
Zurzeit kann die Wartezeit zwischen 1 und 30 Sekunden eingestellt werden.
2. Die Verwendung eines Proxy-Servers
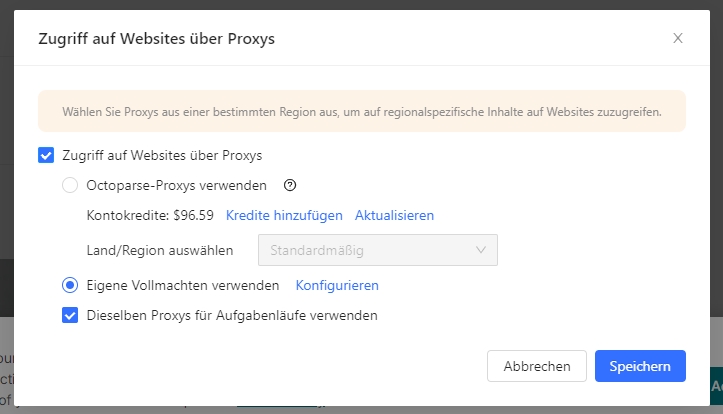
Wenn eine Website eine große Anzahl von Anfragen von einer einzigen IP-Adresse feststellt, ist es wahrscheinlicher, dass diese IP-Adresse blockiert wird. Die Verwendung eines „Proxy-Servers“ kann ein wirksames Mittel sein, um zu vermeiden, dass alle Anfragen von derselben IP-Adresse ausgehen.
Ein Proxy-Server ist ein Server, der mit anderen Servern im Namen anderer Computer kommuniziert. Das bedeutet, dass Sie Ihre echte IP-Adresse verbergen und Ihre konfigurierte IP-Adresse verwenden können, um Anfragen an Websites zu senden.
Die Verwendung einer einzigen auf dem Proxyserver konfigurierten IP-Adresse ändert jedoch nichts an dem Szenario, in dem Ihr Exploit blockiert wird. Daher müssen wir einen Pool von IP-Adressen erstellen und nach dem Zufallsprinzip verschiedene IP-Adressen zum Senden von Anfragen verwenden. Dies wird als IP-Rotation bezeichnet.
Der Octoparse-Cloud-Dienst wird von Hunderten von Cloud-Servern unterstützt, von denen jeder seine eigene IP-Adresse hat. Wenn eine Extraktionsaufgabe in der Cloud ausgeführt werden soll, wird jede Zielseite von einer anderen IP-Adresse aus angefordert, wodurch die Möglichkeit, verfolgt zu werden, minimiert wird. Sie können auch manuell Proxys einrichten, um die Blockierung lokaler Extraktionen zu vermeiden.
3. Verschiedene Scraping-Muster anwenden
Wenn Menschen eine Website durchsuchen, sind Klicks und Verweildauer unregelmäßig. Web Scraping ist jedoch regelmäßig, da es einem bestimmten vorprogrammierten Crawling-Muster folgt. Wenn Scraping verhindert wird, können Crawler leicht entdeckt werden, indem das regelmäßige Scraping-Verhalten auf einer Website identifiziert wird.
Daher muss beim Web-Scraping das Scraping-Muster jedes Mal geändert werden, und es müssen Wartezeiten in den Arbeitsablauf eingebaut werden, um zufällige Klicks, Mausbewegungen, Anfragen usw. menschenähnlicher zu machen.
Mit Octoparse können Sie innerhalb von 3-5 Minuten einen Arbeitsablauf einrichten. Das Hinzufügen von Klicks und Mausbewegungen per Drag-and-Point und die schnelle Umstrukturierung von Arbeitsabläufen spart Entwicklungsingenieuren viel Zeit bei der Programmierung und macht es auch Nicht-Ingenieuren leicht, ihre eigenen Scraper zu erstellen.
Octoparse bietet über 500 benutzerfreundliche Vorlagen, um Daten zu extrahieren. Über 30.000 Nutzer verwenden die Vorlagen
https://www.octoparse.de/template/google-maps-scraper-store-details-by-keyword
4. Wechsel des User Agents
Ein User Agent (UA) ist eine Zeichenkette in der Kopfzeile einer Anfrage, die den Browser und das Betriebssystem gegenüber dem Webserver identifiziert Jede Anfrage eines Webbrowsers enthält einen User Agent.
Das Senden einer ungewöhnlich großen Anzahl von Anfragen mit nur einem User Agent kann zu einer Blockierung führen. Um eine Blockierung zu vermeiden, muss der User-Agent häufig gewechselt werden.
Viele Programmierer fügen gefälschte User-Agents zum Header hinzu oder erstellen manuell eine Liste von User-Agents, um eine Blockierung zu vermeiden; Octoparse kann verwendet werden, um den User-Agent-Wechsel zu automatisieren und so das Risiko einer Blockierung zu verringern. Octoparse kann verwendet werden, um den Wechsel von Benutzer-Agenten zu automatisieren und so das Risiko, blockiert zu werden, zu verringern.
5. Hüten Sie sich vor Honeypot-Fallen
Honeypots sind eine Methode zur gründlichen Überwachung von Geräten, die absichtlich so eingerichtet wurden, dass sie für unbefugte Zugriffe oder Cyberangriffe anfällig sind, und zur Analyse ihrer Funktionsweise.
Es handelt sich um Links, die für normale Besucher unsichtbar sind, im HTML-Code stehen und von Web-Scrapern gefunden werden können. Das heißt, wenn ein Scraper eine Honeypot-Seite aufruft, kann die Website erkennen, dass es sich nicht um einen menschlichen Besucher handelt, und unterdrückt oder blockiert alle Anfragen dieses Clients.
Wenn Sie einen Scraper für eine bestimmte Website erstellen, sollten Sie sorgfältig prüfen, ob es versteckte Links für Benutzer gibt, die einen Standardbrowser verwenden.
Octoparse verwendet XPath für genaue Erfassungs- und Klickoperationen, um das Klicken auf falsche Links zu vermeiden. Weitere Informationen finden Sie in dem Artikel Wie man Elemente mit XPath findet.
Andere häufig gestellte Fragen
Frage 1: Wird das Schaben mit Selen aufgedeckt? Was passiert, wenn ich erwischt werde?
Antwort: Web Scraping mit Selenium ist legal, solange es nicht gegen die Nutzungsbedingungen der Website verstößt. Wenn der Eigentümer der Website das Scraping jedoch entdeckt, können Zugangsbeschränkungen oder rechtliche Schritte eingeleitet werden. Es ist wichtig, beim Scraping vorsichtig zu sein, die Nutzungsbedingungen einzuhalten und es für legitime Zwecke zu nutzen.
Frage 2: Wird der Server der Website durch Scraping belastet?
Antwort: Scraping kann den Server einer Website überlasten. Das Senden einer großen Anzahl von Anfragen in einem kurzen Zeitraum kann den Server überlasten, was zu schlechter Leistung und vorübergehender Unerreichbarkeit führen kann. Es ist wichtig, die richtige Etikette zu beachten, die Intervalle zwischen den Anfragen anzupassen und die Parallelverarbeitung zu begrenzen. Es ist auch wichtig zu wissen, dass der Eigentümer der Website Scraping erkennen und den Zugang beschränken kann.
Zusammenfassung
In diesem Artikel wurden fünf Maßnahmen vorgestellt, um die Entdeckung von Web-Scraping durch andere Server zu verhindern. Web Scraping ist grundsätzlich nicht strafbar, jedoch kann es in bestimmten Anwendungen rechtliche Risiken mit sich bringen, weshalb Vorsicht geboten ist. Die beschriebenen Methoden sind zwar nicht perfekt, können jedoch helfen, Web Scraping unentdeckt zu halten.
Besonders hervorzuheben ist Octoparse, das einen Proxy-Dienst anbietet und es allen Nutzern ermöglicht, anpassbare Proxys hinzuzufügen. Für einen angemessenen Preis lässt sich somit eigener Proxy-Traffic für individuelle Zwecke nutzen.
👍👍 Wenn Sie Interesse an Octoparse und Web Scraping haben, können Sie es zunächst 14 Tage lang kostenlos ausprobieren.
Wenn Sie Probleme bei der Datenextraktion haben, oder uns etwas Vorschlägen geben möchten, kontaktieren Sie bitte uns per E-Mail (support@octoparse.com). 💬

Konvertiere Website-Daten direkt in Excel, CSV, Google Sheets und Ihre Datenbank.
Scrape Daten einfach mit Auto-Dedektion, ganz ohne Coding.
Scraping-Vorlagen für beliebte Websites, um Daten mit wenigen Klicks zu erhalten.
Mit IP-Proxys und fortschrittlicher API wird nie blockiert.
Cloud-Dienst zur Planung von Datenabfragen zu jedem gewünschten Zeitpunkt.



